


















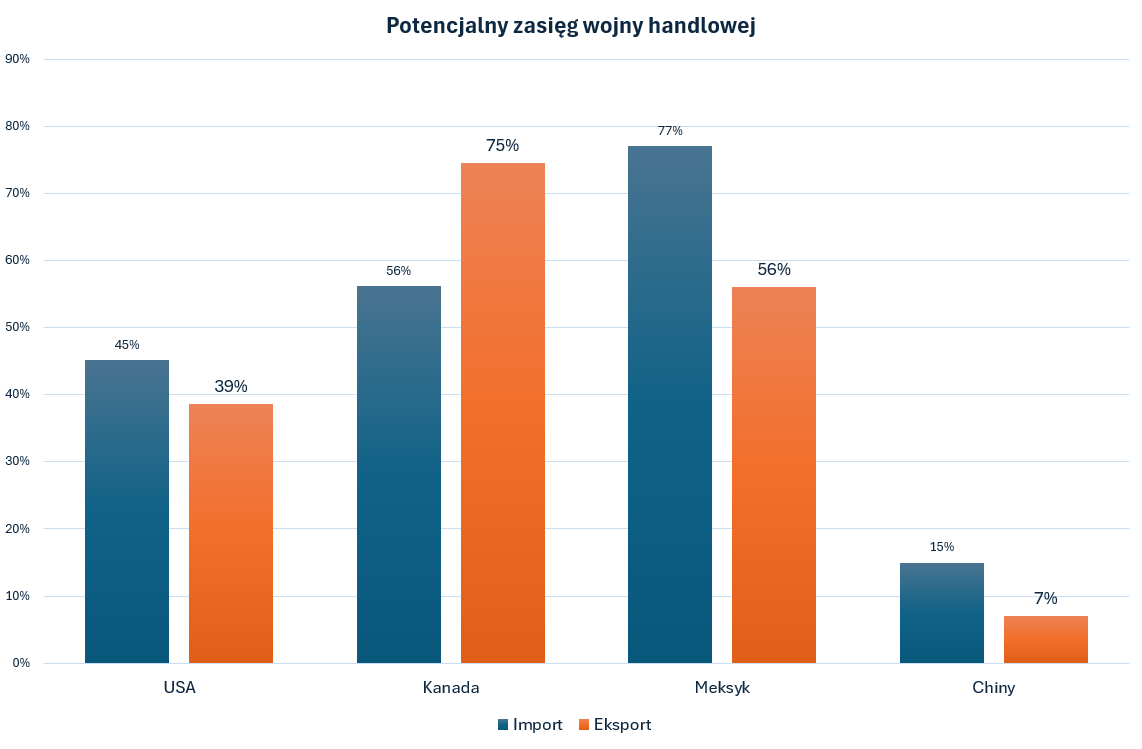





































OpenAI oskarża DeepSeek o naruszenia własności intelektualnej
OpenAI wysuwa wobec swojego chińskiego konkurenta dość poważne oskarżenia. W grze są rzecz jasna wielkie pieniądze, ale stawką jest przede wszystkim zwycięstwo w walce o prym w branży AI. W poniedziałek wśród entuzjastów i przedsiębiorców związanych ze sztuczną inteligencją, a w sposób najbardziej widowiskowy na Wall Street mogliśmy obserwować paniczne ruchy. Teraz gdy zaczyna opadać kurz i firmie DeepSeek zaczynają się przyglądać analitycy, badacze, agencje rządowe i konkurencyjne firmy okazuje się, że skala sukcesu chińskiej platformy nie jest tak ogromna jak jeszcze przed chwilą się wydawało. „That escalated quickly” chciałoby się powiedzieć, patrząc na reakcje świata na niebywałe zamieszanie wywołane chińskim modelem AI, którego popularność eksplodowała w ubiegły weekend. Po początkowej panice na rynku przyszło otrzeźwienie, chłodne kalkulacje i pierwsze oskarżenia o stosowanie nieuczciwych praktyk. DeepSeek destylował dane OpenAI? Do stworzenia dobrego modelu AI potrzebne są co najmniej dwie rzeczy. Potężna ilość danych i wielka moc obliczeniowa. Chińczycy twierdzą, że ich najgłośniejsze dzieło ostatnich dni powstało w zaledwie dwa miesiące i co potwierdzają niektóre benchmarki, faktycznie DeepSeek R1 w wielu aspektach nie ustępuje jakością rozwiązaniom amerykańskim, których projektowanie, trenowanie i tuningowanie pochłonęło znacznie więcej czasu i pieniędzy. DeepSeek nie jest przy tym firmą rozmiarów Facebooka czy Microsoftu, a co za tym idzie o pozyskanie danych treningowych nie było tak łatwo jak Amerykanom. https://dailyweb.pl/memory-boost-od-meta-ai-ktore-zna-cie-lepiej-niz-rodzina/ Brytyjski Financial Times poinformował właśnie, że OpenAI oskarżyło chińską firmę o nielegalne działania polegająca na „destylowaniu” danych pochodzących z modeli takich jak ChatGPT. Chodzi o to, że twórcy DeepSeek R1 poszli nieco na skróty i pozyskali część źródeł treningowych w nienaturalny sposób. Wykorzystali po prostu dane wyjściowe dostarczone przez ChatGPT i następnie umieścili tę wiedzę w swoich zasobach. Proces destylowania nie jest czymś niezwykłym w tej branży i jest powszechnie stosowany przez start-upy AI, ale w tym przypadku doszło do czegoś poważniejszego, bowiem „cudze” dane zostały wykorzystane do stworzenia konkurencyjnego modelu, a to stanowi już naruszenie warunków korzystania z narzędzi OpenAI. Ritwik Gupta, doktorant w dziedzinie sztucznej inteligencji na Uniwersytecie Kalifornijskim w Berkeley tak skomentował te doniesienia: Jest to bardzo powszechna praktyka dla start-upów i naukowców, aby wykorzystywać wyniki komercyjnych LLM zorientowanych na człowieka, takich jak ChatGPT, do trenowania innego modelu. Oznacza to, że otrzymujesz tę ludzką informację zwrotną za darmo. Nie jest dla mnie zaskoczeniem, że DeepSeek rzekomo robi to samo. Gdyby tak było, powstrzymanie tej praktyki może być trudne Co ciekawe, Bloomberg podał informację, że Microsoft i OpenAI już w sierpniu miały odkryć pewne nadużycia i zdecydowały się na zablokowanie podejrzanych kont właśnie ze względu na naruszenia warunków świadczenia usług. Obecnie domniema się, że konta te były powiązane z działalnością DeepSeek. Jak na razie jednak obie firmy nie chcą dzielić się z opinią publiczną szczegółami na temat i nie ujawniają żadnych dowodów. Uczciwość OpenAI także jest kwestionowana W całej tej sprawie nie może umknąć nam fakt, że amerykańska firma stojąca za ChatemGPT, która oskarża swojego rywala o kradzież danych i naruszenia własności intelektualnej sama mierzy się z podobnymi zarzutami. Na rozstrzygnięcie wciąż czekają pozwy sądowe wytoczone przez, chociażby The New York Times i niemałą grupę dziennikarzy i pisarzy, którzy twierdzą, że OpenAI bezprawnie szkoliła swoje modele językowe na pisanych przez nich artykułach i książkach. Ciekawe zatem jak w tym kontekście przed zarzutami będzie bronił się DeepSeek. Pewne jest jednak, że wkrótce czekają nas kolejne odsłony tego konfliktu.

OpenAI wysuwa wobec swojego chińskiego konkurenta dość poważne oskarżenia. W grze są rzecz jasna wielkie pieniądze, ale stawką jest przede wszystkim zwycięstwo w walce o prym w branży AI.
W poniedziałek wśród entuzjastów i przedsiębiorców związanych ze sztuczną inteligencją, a w sposób najbardziej widowiskowy na Wall Street mogliśmy obserwować paniczne ruchy. Teraz gdy zaczyna opadać kurz i firmie DeepSeek zaczynają się przyglądać analitycy, badacze, agencje rządowe i konkurencyjne firmy okazuje się, że skala sukcesu chińskiej platformy nie jest tak ogromna jak jeszcze przed chwilą się wydawało. „That escalated quickly” chciałoby się powiedzieć, patrząc na reakcje świata na niebywałe zamieszanie wywołane chińskim modelem AI, którego popularność eksplodowała w ubiegły weekend. Po początkowej panice na rynku przyszło otrzeźwienie, chłodne kalkulacje i pierwsze oskarżenia o stosowanie nieuczciwych praktyk.
DeepSeek destylował dane OpenAI?
Do stworzenia dobrego modelu AI potrzebne są co najmniej dwie rzeczy. Potężna ilość danych i wielka moc obliczeniowa. Chińczycy twierdzą, że ich najgłośniejsze dzieło ostatnich dni powstało w zaledwie dwa miesiące i co potwierdzają niektóre benchmarki, faktycznie DeepSeek R1 w wielu aspektach nie ustępuje jakością rozwiązaniom amerykańskim, których projektowanie, trenowanie i tuningowanie pochłonęło znacznie więcej czasu i pieniędzy. DeepSeek nie jest przy tym firmą rozmiarów Facebooka czy Microsoftu, a co za tym idzie o pozyskanie danych treningowych nie było tak łatwo jak Amerykanom. https://dailyweb.pl/memory-boost-od-meta-ai-ktore-zna-cie-lepiej-niz-rodzina/ Brytyjski Financial Times poinformował właśnie, że OpenAI oskarżyło chińską firmę o nielegalne działania polegająca na „destylowaniu” danych pochodzących z modeli takich jak ChatGPT. Chodzi o to, że twórcy DeepSeek R1 poszli nieco na skróty i pozyskali część źródeł treningowych w nienaturalny sposób. Wykorzystali po prostu dane wyjściowe dostarczone przez ChatGPT i następnie umieścili tę wiedzę w swoich zasobach. Proces destylowania nie jest czymś niezwykłym w tej branży i jest powszechnie stosowany przez start-upy AI, ale w tym przypadku doszło do czegoś poważniejszego, bowiem „cudze” dane zostały wykorzystane do stworzenia konkurencyjnego modelu, a to stanowi już naruszenie warunków korzystania z narzędzi OpenAI. Ritwik Gupta, doktorant w dziedzinie sztucznej inteligencji na Uniwersytecie Kalifornijskim w Berkeley tak skomentował te doniesienia:Jest to bardzo powszechna praktyka dla start-upów i naukowców, aby wykorzystywać wyniki komercyjnych LLM zorientowanych na człowieka, takich jak ChatGPT, do trenowania innego modelu. Oznacza to, że otrzymujesz tę ludzką informację zwrotną za darmo. Nie jest dla mnie zaskoczeniem, że DeepSeek rzekomo robi to samo. Gdyby tak było, powstrzymanie tej praktyki może być trudne


