









![From freeCodeCamp to CTO with Robotics Engineer Peggy Wang [Podcast #159]](https://cdn.hashnode.com/res/hashnode/image/upload/v1738967132406/6ab8c7bb-397a-42b3-bb91-ff9c4842ead0.png?#)























































Unraveling Direct Alignment Algorithms: A Comparative Study on Optimization Strategies for LLM Alignment
Aligning large language models (LLMs) with human values remains difficult due to unclear goals, weak training signals, and the complexity of human intent. Direct Alignment Algorithms (DAAs) offer a way to simplify this process by optimizing models directly without relying on reward modeling or reinforcement learning. These algorithms use different ranking methods, such as comparing […] The post Unraveling Direct Alignment Algorithms: A Comparative Study on Optimization Strategies for LLM Alignment appeared first on MarkTechPost.



Aligning large language models (LLMs) with human values remains difficult due to unclear goals, weak training signals, and the complexity of human intent. Direct Alignment Algorithms (DAAs) offer a way to simplify this process by optimizing models directly without relying on reward modeling or reinforcement learning. These algorithms use different ranking methods, such as comparing pairs of outputs or scoring individual responses. Some versions also require an extra fine-tuning step, while others do not. There are further complications in understanding how effective they are and which approach is best because of differences in how rewards are defined and applied.
Currently, methods for aligning large language models (LLMs) follow multiple steps, including supervised fine-tuning (SFT), reward modeling, and reinforcement learning. These methods introduce challenges due to their complexity, dependence on reward models, and high computational cost. DAAs try to optimize models from human preferences directly, bypassing reinforcement learning and reward modeling. Different forms of DAAs may vary in their optimization method, loss functions, and fine-tuning method. Despite their potential to simplify alignment, inconsistencies in ranking methods, reward calculations, and training strategies create further difficulties in evaluating their effectiveness.
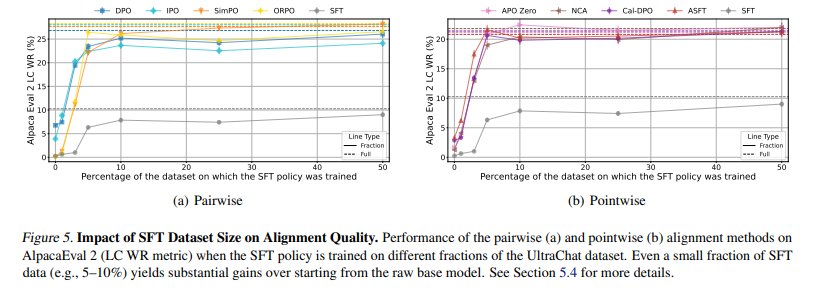
To improve single-stage direct alignment algorithms (DAAs) like ORPO and ASFT, researchers proposed adding a separate supervised fine-tuning (SFT) phase and introducing a scaling parameter (β). These methods were originally not provided with a β parameter and did alignment directly. As such, they were less effective. Including an explicit SFT phase and letting β control preference scaling gives these methods performance comparable to two-stage approaches such as DPO. The main distinction between different DAAs lies in whether they use an odds ratio or a reference policy ratio, which affects how alignment is optimized.
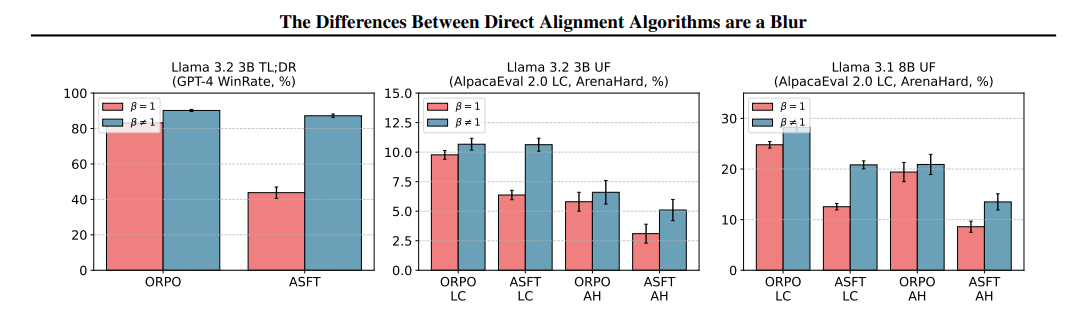
The framework modifies the loss functions of ASFT and ORPO to include SFT in an implicit way, making them adaptable to single-stage and two-stage configurations. The scaling parameter β is used to adjust the strength of preference updates toward better control in optimization. Experimental analysis suggests that DAAs relying on pairwise comparisons outperform those relying on pointwise preferences, thus warranting structured ranking signals in alignment quality.

Researchers evaluated Direct Alignment Algorithms (DAA) using Llama 3.1 8B on UltraChat and UF datasets, testing on AlpacaEval 2 and ArenaHard, while Llama 3.2 3B was used for Reddit TL; DR. Supervised fine-tuning (SFT) on UF improved ORPO and ASFT alignment. ORPO performed on par with DPO and ASFT, achieving a +2.04% increase in ArenaHard win rate but still lagging behind ORPO. β tuning significantly enhanced performance, yielding improvements of +7.0 and +43.4 in GPT-4 win rate for TL;DR and +3.46 and +8.27 in UF AlpacaEval 2 LC win rate. Comparative analysis of DPO, IPO, SimPO, and other alignment methods showed that β adjustments in LβASFTAlign and LβORPOAlign improved preference optimization, demonstrating that SFT-trained models performed best when incorporating LAlign components.
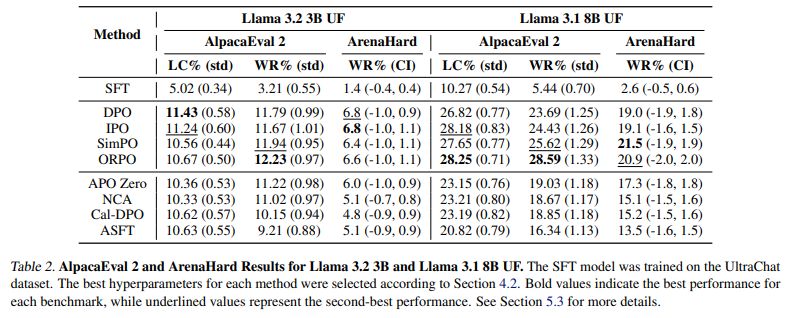
In the end, the proposed method improved Direct Alignment Algorithms (DAAs) by incorporating a supervised fine-tuning (SFT) phase. This led to consistent performance gains and significantly enhanced ORPO and ASFT. Even though the evaluation was conducted on specific datasets and model sizes, the findings provide a structured approach for improving model alignment. This method is a foundation to be used as a basis for future research. It can be extrapolated to other larger models with more diverse data sets to refine alignment techniques through optimization strategies that identify factors in alignment quality.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 75k+ ML SubReddit.









