

































































Stop Creating Bad DAGs — Optimize Your Airflow Environment By Improving Your Python Code
Stop Creating Bad DAGs — Optimize Your Airflow Environment By Improving Your Python CodeValuable tips to reduce your DAGs’ parse time and save resources.Photo by Dan Roizer on UnsplashApache Airflow is one of the most popular orchestration tools in the data field, powering workflows for companies worldwide. However, anyone who has already worked with Airflow in a production environment, especially in a complex one, knows that it can occasionally present some problems and weird bugs.Among the many aspects you need to manage in an Airflow environment, one critical metric often flies under the radar: DAG parse time. Monitoring and optimizing parse time is essential to avoid performance bottlenecks and ensure the correct functioning of your orchestrations, as we’ll explore in this article.That said, this tutorial aims to introduce airflow-parse-bench, an open-source tool I developed to help data engineers monitor and optimize their Airflow environments, providing insights to reduce code complexity and parse time.Why Parse Time MattersRegarding Airflow, DAG parse time is often an overlooked metric. Parsing occurs every time Airflow processes your Python files to build the DAGs dynamically.By default, all your DAGs are parsed every 30 seconds — a frequency controlled by the configuration variable min_file_process_interval. This means that every 30 seconds, all the Python code that’s present in your dags folder is read, imported, and processed to generate DAG objects containing the tasks to be scheduled. Successfully processed files are then added to the DAG Bag.Two key Airflow components handle this process:DagFileProcessorManager: Checks which files need to be processed.DagFileProcessorProcess: Executes the actual file parsing.Together, both components (commonly referred to as the dag processor) are executed by the Airflow Scheduler, ensuring that your DAG objects are updated before being triggered. However, for scalability and security reasons, it is also possible to run your dag processor as a separate component in your cluster.If your environment only has a few dozen DAGs, it’s unlikely that the parsing process will cause any kind of problem. However, it’s common to find production environments with hundreds or even thousands of DAGs. In this case, if your parse time is too high, it can lead to:Delay DAG scheduling.Increase resource utilization.Environment heartbeat issues.Scheduler failures.Excessive CPU and memory usage, wasting resources.Now, imagine having an environment with hundreds of DAGs containing unnecessarily complex parsing logic. Small inefficiencies can quickly turn into significant problems, affecting the stability and performance of your entire Airflow setup.How to write better DAGs?When writing Airflow DAGs, there are some important best practices to bear in mind to create optimized code. Although you can find a lot of tutorials on how to improve your DAGs, I’ll summarize some of the key principles that can significantly enhance your DAG performance.Limit Top-Level CodeOne of the most common causes of high DAG parsing times is inefficient or complex top-level code. Top-level code in an Airflow DAG file is executed every time the Scheduler parses the file. If this code includes resource-intensive operations, such as database queries, API calls, or dynamic task generation, it can significantly impact parsing performance.The following code shows an example of a non-optimized DAG:https://medium.com/media/003b2f1bc628053515b19cb24b159bd1/hrefIn this case, every time the file is parsed by the Scheduler, the top-level code is executed, making an API request and processing the DataFrame, which can significantly impact the parse time.Another important factor contributing to slow parsing is top-level imports. Every library imported at the top level is loaded into memory during parsing, which can be time-consuming. To avoid this, you can move imports into functions or task definitions.The following code shows a better version of the same DAG:https://medium.com/media/5258f82b5ea607bde0a8494fb70717ae/hrefAvoid Xcoms and Variables in Top-Level CodeStill talking about the same topic, is particularly interesting to avoid using Xcoms and Variables in your top-level code. As stated by Google documentation:If you are using Variable.get() in top level code, every time the .py file is parsed, Airflow executes a Variable.get() which opens a session to the DB. This can dramatically slow down parse times.To address this, consider using a JSON dictionary to retrieve multiple variables in a single database query, rather than making multiple Variable.get() calls. Alternatively, use Jinja templates, as variables retrieved this way are only processed during task execution, not during DAG parsing.Remove Unnecessary DAGsAlthough it seems obvious, it’s always important to remember to periodically clean up unnecessary DAGs and files from your environment:Remove unused DAGs: Check your dags folder and delete any files that a

Stop Creating Bad DAGs — Optimize Your Airflow Environment By Improving Your Python Code
Valuable tips to reduce your DAGs’ parse time and save resources.
Apache Airflow is one of the most popular orchestration tools in the data field, powering workflows for companies worldwide. However, anyone who has already worked with Airflow in a production environment, especially in a complex one, knows that it can occasionally present some problems and weird bugs.
Among the many aspects you need to manage in an Airflow environment, one critical metric often flies under the radar: DAG parse time. Monitoring and optimizing parse time is essential to avoid performance bottlenecks and ensure the correct functioning of your orchestrations, as we’ll explore in this article.
That said, this tutorial aims to introduce airflow-parse-bench, an open-source tool I developed to help data engineers monitor and optimize their Airflow environments, providing insights to reduce code complexity and parse time.
Why Parse Time Matters
Regarding Airflow, DAG parse time is often an overlooked metric. Parsing occurs every time Airflow processes your Python files to build the DAGs dynamically.
By default, all your DAGs are parsed every 30 seconds — a frequency controlled by the configuration variable min_file_process_interval. This means that every 30 seconds, all the Python code that’s present in your dags folder is read, imported, and processed to generate DAG objects containing the tasks to be scheduled. Successfully processed files are then added to the DAG Bag.
Two key Airflow components handle this process:
- DagFileProcessorManager: Checks which files need to be processed.
- DagFileProcessorProcess: Executes the actual file parsing.
Together, both components (commonly referred to as the dag processor) are executed by the Airflow Scheduler, ensuring that your DAG objects are updated before being triggered. However, for scalability and security reasons, it is also possible to run your dag processor as a separate component in your cluster.
If your environment only has a few dozen DAGs, it’s unlikely that the parsing process will cause any kind of problem. However, it’s common to find production environments with hundreds or even thousands of DAGs. In this case, if your parse time is too high, it can lead to:
- Delay DAG scheduling.
- Increase resource utilization.
- Environment heartbeat issues.
- Scheduler failures.
- Excessive CPU and memory usage, wasting resources.
Now, imagine having an environment with hundreds of DAGs containing unnecessarily complex parsing logic. Small inefficiencies can quickly turn into significant problems, affecting the stability and performance of your entire Airflow setup.
How to write better DAGs?
When writing Airflow DAGs, there are some important best practices to bear in mind to create optimized code. Although you can find a lot of tutorials on how to improve your DAGs, I’ll summarize some of the key principles that can significantly enhance your DAG performance.
Limit Top-Level Code
One of the most common causes of high DAG parsing times is inefficient or complex top-level code. Top-level code in an Airflow DAG file is executed every time the Scheduler parses the file. If this code includes resource-intensive operations, such as database queries, API calls, or dynamic task generation, it can significantly impact parsing performance.
The following code shows an example of a non-optimized DAG:https://medium.com/media/003b2f1bc628053515b19cb24b159bd1/href
In this case, every time the file is parsed by the Scheduler, the top-level code is executed, making an API request and processing the DataFrame, which can significantly impact the parse time.
Another important factor contributing to slow parsing is top-level imports. Every library imported at the top level is loaded into memory during parsing, which can be time-consuming. To avoid this, you can move imports into functions or task definitions.
The following code shows a better version of the same DAG:https://medium.com/media/5258f82b5ea607bde0a8494fb70717ae/href
Avoid Xcoms and Variables in Top-Level Code
Still talking about the same topic, is particularly interesting to avoid using Xcoms and Variables in your top-level code. As stated by Google documentation:
If you are using Variable.get() in top level code, every time the .py file is parsed, Airflow executes a Variable.get() which opens a session to the DB. This can dramatically slow down parse times.
To address this, consider using a JSON dictionary to retrieve multiple variables in a single database query, rather than making multiple Variable.get() calls. Alternatively, use Jinja templates, as variables retrieved this way are only processed during task execution, not during DAG parsing.
Remove Unnecessary DAGs
Although it seems obvious, it’s always important to remember to periodically clean up unnecessary DAGs and files from your environment:
- Remove unused DAGs: Check your dags folder and delete any files that are no longer needed.
- Use .airflowignore: Specify the files Airflow should intentionally ignore, skipping parsing.
- Review paused DAGs: Paused DAGs are still parsed by the Scheduler, consuming resources. If they are no longer required, consider removing or archiving them.
Change Airflow Configurations
Lastly, you could change some Airflow configurations to reduce the Scheduler resource usage:
- min_file_process_interval: This setting controls how often (in seconds) Airflow parses your DAG files. Increasing it from the default 30 seconds can reduce the Scheduler's load at the cost of slower DAG updates.
- dag_dir_list_interval: This determines how often (in seconds) Airflow scans the dags directory for new DAGs. If you deploy new DAGs infrequently, consider increasing this interval to reduce CPU usage.
How to Measure DAG Parse Time?
We’ve discussed a lot about the importance of creating optimized DAGs to maintain a healthy Airflow environment. But how do you actually measure the parse time of your DAGs? Fortunately, there are several ways to do this, depending on your Airflow deployment or operating system.
For example, if you have a Cloud Composer deployment, you can easily retrieve a DAG parse report by executing the following command on Google CLI:
gcloud composer environments run $ENVIRONMENT_NAME \
— location $LOCATION \
dags report
While retrieving parse metrics is straightforward, measuring the effectiveness of your code optimizations can be less so. Every time you modify your code, you need to redeploy the updated Python file to your cloud provider, wait for the DAG to be parsed, and then extract a new report — a slow and time-consuming process.
Another possible approach, if you’re on Linux or Mac, is to run this command to measure the parse time locally on your machine:
time python airflow/example_dags/example.py
However, while simple, this approach is not practical for systematically measuring and comparing the parse times of multiple DAGs.
To address these challenges, I created the airflow-parse-bench, a Python library that simplifies measuring and comparing the parse times of your DAGs using Airflow's native parse method.
Measuring and Comparing Your DAG’s Parse Times
The airflow-parse-bench tool makes it easy to store parse times, compare results, and standardize comparisons across your DAGs.
Installing the Library
Before installation, it’s recommended to use a virtualenv to avoid library conflicts. Once set up, you can install the package by running the following command:
pip install airflow-parse-bench
Note: This command only installs the essential dependencies (related to Airflow and Airflow providers). You must manually install any additional libraries your DAGs depend on.
For example, if a DAG uses boto3 to interact with AWS, ensure that boto3 is installed in your environment. Otherwise, you'll encounter parse errors.
After that, it's necessary to initialize your Airflow database. This can be done by executing the following command:
airflow db init
In addition, if your DAGs use Airflow Variables, you must define them locally as well. However, it’s not necessary to put real values on your variables, as the actual values aren’t required for parsing purposes:
airflow variables set MY_VARIABLE 'ANY TEST VALUE'
Without this, you’ll encounter an error like:
error: 'Variable MY_VARIABLE does not exist'
Using the Tool
After installing the library, you can begin measuring parse times. For example, suppose you have a DAG file named dag_test.py containing the non-optimized DAG code used in the example above.
To measure its parse time, simply run:
airflow-parse-bench --path dag_test.py
This execution produces the following output:
As observed, our DAG presented a parse time of 0.61 seconds. If I run the command again, I’ll see some small differences, as parse times can vary slightly across runs due to system and environmental factors:
In order to present a more concise number, it’s possible to aggregate multiple executions by specifying the number of iterations:
airflow-parse-bench --path dag_test.py --num-iterations 5
Although it takes a bit longer to finish, this calculates the average parse time across five executions.
Now, to evaluate the impact of the aforementioned optimizations, I replaced the code in mydag_test.py with the optimized version shared earlier. After executing the same command, I got the following result:
As noticed, just applying some good practices was capable of reducing almost 0.5 seconds in the DAG parse time, highlighting the importance of the changes we made!
Further Exploring the Tool
There are other interesting features that I think it’s relevant to share.
As a reminder, if you have any doubts or problems using the tool, you can access the complete documentation on GitHub.
Besides that, to view all the parameters supported by the library, simply run:
airflow-parse-bench --help
Testing Multiple DAGs
In most cases, you likely have dozens of DAGs to test the parse times. To address this use case, I created a folder named dags and put four Python files inside it.
To measure the parse times for all the DAGs in a folder, it's just necessary to specify the folder path in the --path parameter:
airflow-parse-bench --path my_path/dags
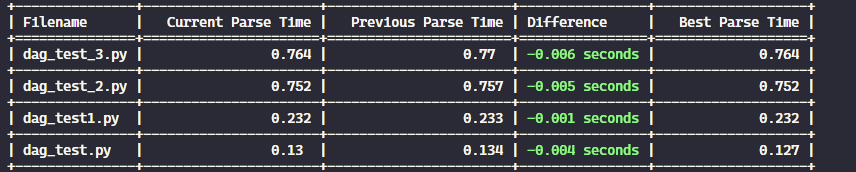
Running this command produces a table summarizing the parse times for all the DAGs in the folder:
By default, the table is sorted from the fastest to the slowest DAG. However, you can reverse the order by using the --order parameter:
airflow-parse-bench --path my_path/dags --order desc
Skipping Unchanged DAGs
The --skip-unchanged parameter can be especially useful during development. As the name suggests, this option skips the parse execution for DAGs that haven't been modified since the last execution:
airflow-parse-bench --path my_path/dags --skip-unchanged
As shown below, when the DAGs remain unchanged, the output reflects no difference in parse times:
Resetting the Database
All DAG information, including metrics and history, is stored in a local SQLite database. If you want to clear all stored data and start fresh, use the --reset-db flag:
airflow-parse-bench --path my_path/dags --reset-db
This command resets the database and processes the DAGs as if it were the first execution.
Conclusion
Parse time is an important metric for maintaining scalable and efficient Airflow environments, especially as your orchestration requirements become increasingly complex.
For this reason, the airflow-parse-bench library can be an important tool for helping data engineers create better DAGs. By testing your DAGs' parse time locally, you can easily and quickly find your code bottleneck, making your dags faster and more performant.
Since the code is executed locally, the produced parse time won’t be the same as the one present in your Airflow cluster. However, if you are able to reduce the parse time in your local machine, the same might be reproduced in your cloud environment.
Finally, this project is open for collaboration! If you have suggestions, ideas, or improvements, feel free to contribute on GitHub.
References
- maximize the benefits of Cloud Composer and reduce parse times | Google Cloud Blog
- Optimize Cloud Composer via Better Airflow DAGs | Google Cloud Blog
- Scheduler - Airflow Documentation
- Best Practices - Airflow Documentation
- GitHub - AlvaroCavalcante/airflow-parse-bench: Stop creating bad DAGs! Use this tool to measure and compare the parse time of your DAGs, identify bottlenecks, and optimize your Airflow environment for better performance.
Stop Creating Bad DAGs — Optimize Your Airflow Environment By Improving Your Python Code was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.









