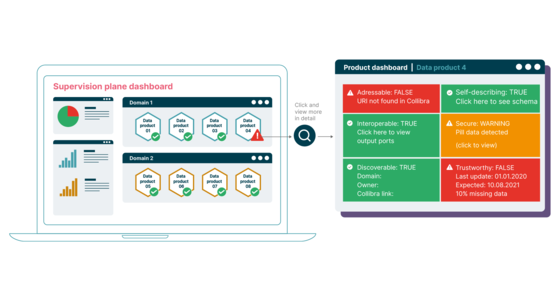































Serverless MapReduce for Excel: Scale Your Marketing Data with AWS
Introduction MapReduce is a programming model for processing large datasets in parallel. It splits the input data into chunks (Map), then combines or aggregates results (Reduce). Map: Break down data into smaller parts. Shuffle/Sort: Group related data. Reduce: Aggregate or combine into final results. Let's learn the Map-Reduce pattern with a real-world example: Event-Driven Serverless “MapReduce” AWS Architecture for Excel-Based Marketing Campaign Analytics. 1. Overview If you’re dealing with Excel sheets full of marketing metrics (e.g., campaigns, CPC, revenue), this AWS serverless pipeline helps process and aggregate data automatically—no cluster management needed. Key Steps: Upload Excel: A marketing manager uploads a spreadsheet to an Amazon S3 bucket. Map Lambda: Parses each row (date, campaign, source, cost, etc.) and saves intermediate results. Reduce Lambda: Aggregates partial data into a final report for analytics or dashboards. 2. Architecture Flow Excel File Upload: The marketing manager or an automated process places the Excel file into an S3 bucket. Map Lambda: Triggered by an S3 event. It reads and parses each row, storing partial outputs in S3. Reduce Lambda: Triggered by a subsequent event or schedule. Collects all partial results, aggregates them, and writes the final report to S3 or a database. 3. Step-by-Step User uploads an Excel file with marketing data to an S3 bucket. Map Lambda is triggered by an S3 event, processes each row, and stores intermediate data. Reduce Lambda aggregates data across different marketing sources into a final report. The processed report can be stored in S3 or used for visualization. 4. Key Benefits ✅ Serverless: No servers or clusters to maintain. ✅ Cost-Effective: Only pay for Lambda execution and minimal S3 usage. ✅ Automated Data Ingestion: Triggers when an Excel file is uploaded. ✅ Decoupled Architecture: Easily modify or extend each step. 5. Next Steps Add validation/error handling in the “Map” phase for missing columns or invalid data. Implement notifications (e.g., email or Slack) when final reports are generated. Integrate with dashboard tools (e.g., QuickSight) to visualize aggregated marketing metrics. 6. Example Transformation Flow Below is a simple example of how a single row from the Excel file is transformed during the Map step, and then combined in the Reduce step.

Introduction
MapReduce is a programming model for processing large datasets in parallel. It splits the input data into chunks (Map), then combines or aggregates results (Reduce).
- Map: Break down data into smaller parts.
- Shuffle/Sort: Group related data.
- Reduce: Aggregate or combine into final results.
Let's learn the Map-Reduce pattern with a real-world example: Event-Driven Serverless “MapReduce” AWS Architecture for Excel-Based Marketing Campaign Analytics.
1. Overview
If you’re dealing with Excel sheets full of marketing metrics (e.g., campaigns, CPC, revenue), this AWS serverless pipeline helps process and aggregate data automatically—no cluster management needed.
Key Steps:
- Upload Excel: A marketing manager uploads a spreadsheet to an Amazon S3 bucket.
- Map Lambda: Parses each row (date, campaign, source, cost, etc.) and saves intermediate results.
- Reduce Lambda: Aggregates partial data into a final report for analytics or dashboards.
2. Architecture Flow
- Excel File Upload: The marketing manager or an automated process places the Excel file into an S3 bucket.
- Map Lambda: Triggered by an S3 event. It reads and parses each row, storing partial outputs in S3.
- Reduce Lambda: Triggered by a subsequent event or schedule. Collects all partial results, aggregates them, and writes the final report to S3 or a database.
3. Step-by-Step

- User uploads an Excel file with marketing data to an S3 bucket.
- Map Lambda is triggered by an S3 event, processes each row, and stores intermediate data.
- Reduce Lambda aggregates data across different marketing sources into a final report.
- The processed report can be stored in S3 or used for visualization.
4. Key Benefits
✅ Serverless: No servers or clusters to maintain.
✅ Cost-Effective: Only pay for Lambda execution and minimal S3 usage.
✅ Automated Data Ingestion: Triggers when an Excel file is uploaded.
✅ Decoupled Architecture: Easily modify or extend each step.
5. Next Steps
- Add validation/error handling in the “Map” phase for missing columns or invalid data.
- Implement notifications (e.g., email or Slack) when final reports are generated.
- Integrate with dashboard tools (e.g., QuickSight) to visualize aggregated marketing metrics.
6. Example Transformation Flow
Below is a simple example of how a single row from the Excel file is transformed during the Map step, and then combined in the Reduce step.