








![Last day of work [closed]](https://cdn.sstatic.net/Sites/workplace/Img/apple-touch-icon@2.png?v=d39b333f5c58)






































![United Lounge Hack: Flyers Are Cooking Up Secret Breakfast Sandwiches—Would You Try It? [Roundup]](https://viewfromthewing.com/wp-content/uploads/2025/01/united-mcmuffin.webp?#)





















Injecting domain expertise into your AI system
How to connect the dots between AI technology and real life(Source: Getty Images)When starting their AI initiatives, many companies are trapped in silos and treat AI as a purely technical enterprise, sidelining domain experts or involving them too late. They end up with generic AI applications that miss industry nuances, produce poor recommendations, and quickly become unpopular with users. By contrast, AI systems that deeply understand industry-specific processes, constraints, and decision logic have the following benefits:Increased efficiency — The more domain knowledge AI incorporates, the less manual effort is required from human experts.Improved adoption — Experts disengage from AI systems that feel too generic. AI must speak their language and align with real workflows to gain trust.A sustainable competitive moat — As AI becomes a commodity, embedding proprietary expertise is the most effective way to build defensible AI systems (cf. this article to learn about the building blocks of AI’s competitive advantage).Domain experts can help you connect the dots between the technicalities of an AI system and its real-life usage and value. Thus, they should be key stakeholders and co-creators of your AI applications. This guide is the first part of my series on expertise-driven AI. Following my mental model of AI systems, it provides a structured approach to embedding deep domain expertise into your AI.Overview of the methods for domain knowledge integrationThroughout the article, we will use the use case of supply chain optimisation (SCO) to illustrate these different methods. Modern supply chains are under constant strain from geopolitical tensions, climate disruptions, and volatile demand shifts, and AI can provide the kind of dynamic, high-coverage intelligence needed to anticipate delays, manage risks, and optimise logistics. However, without domain expertise, these systems are often disconnected from the realities of life. Let’s see how we can solve this by integrating domain expertise across the different components of the AI application.1. Data: The bedrock of expertise-driven AIAI is only as domain-aware as the data it learns from. Raw data isn’t enough — it must be curated, refined, and contextualised by experts who understand its meaning in the real world.Data understanding: Teaching AI what mattersWhile data scientists can build sophisticated models to analyse patterns and distributions, these analyses often stay at a theoretical, abstract level. Only domain experts can validate whether the data is complete, accurate, and representative of real-world conditions.In supply chain optimisation, for example, shipment records may contain missing delivery timestamps, inconsistent route details, or unexplained fluctuations in transit times. A data scientist might discard these as noise, but a logistics expert could have real-world explanations of these inconsistencies. For instance, they might be caused by weather-related delays, seasonal port congestion, or supplier reliability issues. If these nuances aren’t accounted for, the AI might learn an overly simplified view of supply chain dynamics, resulting in misleading risk assessments and poor recommendations.Experts also play a critical role in assessing the completeness of data. AI models work with what they have, assuming that all key factors are already present. It takes human expertise and judgment to identify blind spots. For example, if your supply chain AI isn’t trained on customs clearance times or factory shutdown histories, it won’t be able to predict disruptions caused by regulatory issues or production bottlenecks.✅ Implementation tip: Run joint Exploratory Data Analysis (EDA) sessions with data scientists and domain experts to identify missing business-critical information, ensuring AI models work with a complete and meaningful dataset, not just statistically clean data.Data source selection: Start small, expand strategicallyOne common pitfall when starting with AI is integrating too much data too soon, leading to complexity, congestion of your data pipelines, and blurred or noisy insights. Instead, start with a couple of high-impact data sources and expand incrementally based on AI performance and user needs. For instance, an SCO system may initially use historical shipment data and supplier reliability scores. Over time, domain experts may identify missing information — such as port congestion data or real-time weather forecasts — and point engineers to those data sources where it can be found.✅ Implementation tip: Start with a minimal, high-value dataset (normally 3–5 data sources), then expand incrementally based on expert feedback and real-world AI performance.Data annotationAI models learn by detecting patterns in data, but sometimes, the right learning signals aren’t yet present in raw data. This is where data annotation comes in — by labelling key attributes, domain experts help the AI understand what matters and make better predicti

How to connect the dots between AI technology and real life

When starting their AI initiatives, many companies are trapped in silos and treat AI as a purely technical enterprise, sidelining domain experts or involving them too late. They end up with generic AI applications that miss industry nuances, produce poor recommendations, and quickly become unpopular with users. By contrast, AI systems that deeply understand industry-specific processes, constraints, and decision logic have the following benefits:
- Increased efficiency — The more domain knowledge AI incorporates, the less manual effort is required from human experts.
- Improved adoption — Experts disengage from AI systems that feel too generic. AI must speak their language and align with real workflows to gain trust.
- A sustainable competitive moat — As AI becomes a commodity, embedding proprietary expertise is the most effective way to build defensible AI systems (cf. this article to learn about the building blocks of AI’s competitive advantage).
Domain experts can help you connect the dots between the technicalities of an AI system and its real-life usage and value. Thus, they should be key stakeholders and co-creators of your AI applications. This guide is the first part of my series on expertise-driven AI. Following my mental model of AI systems, it provides a structured approach to embedding deep domain expertise into your AI.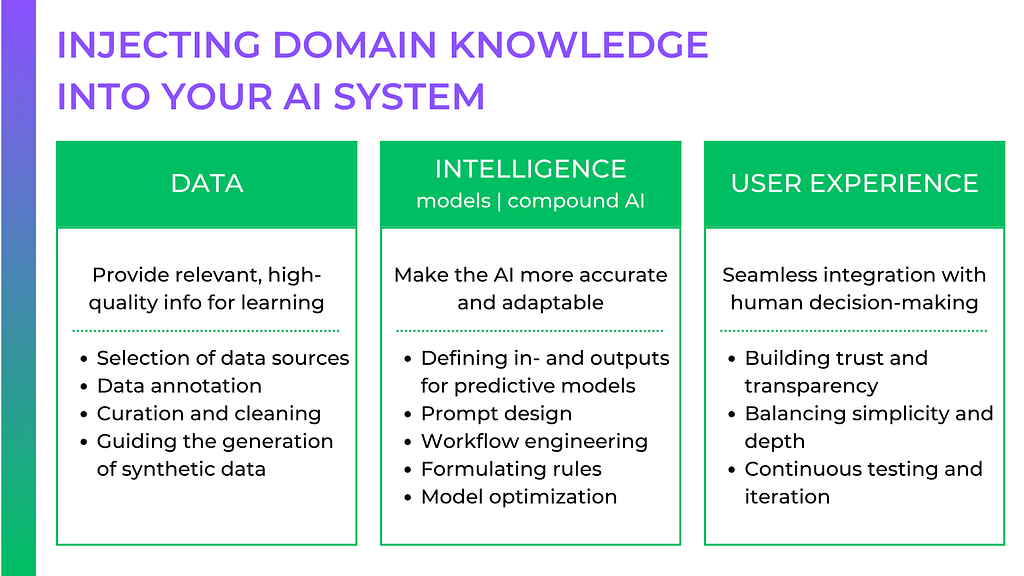
Throughout the article, we will use the use case of supply chain optimisation (SCO) to illustrate these different methods. Modern supply chains are under constant strain from geopolitical tensions, climate disruptions, and volatile demand shifts, and AI can provide the kind of dynamic, high-coverage intelligence needed to anticipate delays, manage risks, and optimise logistics. However, without domain expertise, these systems are often disconnected from the realities of life. Let’s see how we can solve this by integrating domain expertise across the different components of the AI application.
1. Data: The bedrock of expertise-driven AI
AI is only as domain-aware as the data it learns from. Raw data isn’t enough — it must be curated, refined, and contextualised by experts who understand its meaning in the real world.
Data understanding: Teaching AI what matters
While data scientists can build sophisticated models to analyse patterns and distributions, these analyses often stay at a theoretical, abstract level. Only domain experts can validate whether the data is complete, accurate, and representative of real-world conditions.
In supply chain optimisation, for example, shipment records may contain missing delivery timestamps, inconsistent route details, or unexplained fluctuations in transit times. A data scientist might discard these as noise, but a logistics expert could have real-world explanations of these inconsistencies. For instance, they might be caused by weather-related delays, seasonal port congestion, or supplier reliability issues. If these nuances aren’t accounted for, the AI might learn an overly simplified view of supply chain dynamics, resulting in misleading risk assessments and poor recommendations.
Experts also play a critical role in assessing the completeness of data. AI models work with what they have, assuming that all key factors are already present. It takes human expertise and judgment to identify blind spots. For example, if your supply chain AI isn’t trained on customs clearance times or factory shutdown histories, it won’t be able to predict disruptions caused by regulatory issues or production bottlenecks.
✅ Implementation tip: Run joint Exploratory Data Analysis (EDA) sessions with data scientists and domain experts to identify missing business-critical information, ensuring AI models work with a complete and meaningful dataset, not just statistically clean data.
Data source selection: Start small, expand strategically
One common pitfall when starting with AI is integrating too much data too soon, leading to complexity, congestion of your data pipelines, and blurred or noisy insights. Instead, start with a couple of high-impact data sources and expand incrementally based on AI performance and user needs. For instance, an SCO system may initially use historical shipment data and supplier reliability scores. Over time, domain experts may identify missing information — such as port congestion data or real-time weather forecasts — and point engineers to those data sources where it can be found.
✅ Implementation tip: Start with a minimal, high-value dataset (normally 3–5 data sources), then expand incrementally based on expert feedback and real-world AI performance.
Data annotation
AI models learn by detecting patterns in data, but sometimes, the right learning signals aren’t yet present in raw data. This is where data annotation comes in — by labelling key attributes, domain experts help the AI understand what matters and make better predictions. Consider an AI model built to predict supplier reliability. The model is trained on shipment records, which contain delivery times, delays, and transit routes. However, raw delivery data alone doesn’t capture the full picture of supplier risk — there are no direct labels indicating whether a supplier is “high risk” or “low risk.”
Without more explicit learning signals, the AI might make the wrong conclusions. It could conclude that all delays are equally bad, even when some are caused by predictable seasonal fluctuations. Or it might overlook early warning signs of supplier instability, such as frequent last-minute order changes or inconsistent inventory levels.
Domain experts can enrich the data with more nuanced labels, such as supplier risk categories, disruption causes, and exception-handling rules. By introducing these curated learning signals, you can ensure that AI doesn’t just memorise past trends but learns meaningful, decision-ready insights.
You shouldn’t rush your annotation efforts — instead, think about a structured annotation process that includes the following components:
- Annotation guidelines: Establish clear, standardized rules for labeling data to ensure consistency. For example, supplier risk categories should be based on defined thresholds (e.g., delivery delays over 5 days + financial instability = high risk).
- Multiple expert review: Involve several domain experts to reduce bias and ensure objectivity, particularly for subjective classifications like risk levels or disruption impact.
- Granular labelling: Capture both direct and contextual factors, such as annotating not just shipment delays but also the cause (customs, weather, supplier fault).
- Continuous refinement: Regularly audit and refine annotations based on AI performance — if predictions consistently miss key risks, experts should adjust labelling strategies accordingly.
✅ Implementation tip: Define an annotation playbook with clear labelling criteria, involve at least two domain experts per critical label for objectivity, and run regular annotation review cycles to ensure AI is learning from accurate, business-relevant insights.
Synthetic data: Preparing AI for rare but critical events
So far, our AI models learn from real-life historical data. However, rare, high-impact events — like factory shutdowns, port closures, or regulatory shifts in our supply chain scenario — may be underrepresented. Without exposure to these scenarios, AI can fail to anticipate major risks, leading to overconfidence in supplier stability and poor contingency planning. Synthetic data solves this by creating more datapoints for rare events, but expert oversight is crucial to ensure that it reflects plausible risks rather than unrealistic patterns.
Let’s say we want to predict supplier reliability in our supply chain system. The historical data may have few recorded supplier failures — but that’s not because failures don’t happen. Rather, many companies proactively mitigate risks before they escalate. Without synthetic examples, AI might deduce that supplier defaults are extremely rare, leading to misguided risk assessments.
Experts can help generate synthetic failure scenarios based on:
- Historical patterns — Simulating supplier collapses triggered by economic downturns, regulatory shifts, or geopolitical tensions.
- Hidden risk indicators — Training AI on unrecorded early warning signs, like financial instability or leadership changes.
- Counterfactuals — Creating “what-if” events, such as a semiconductor supplier suddenly halting production or a prolonged port strike.
✅ Actionable step: Work with domain experts to define high-impact but low-frequency events and scenarios, which can be in focus when you generate synthetic data.
Data makes domain expertise shine. An AI initiative that relies on clean, relevant, and enriched domain data will have an obvious competitive advantage over one that takes the “quick-and-dirty” shortcut to data. However, keep in mind that working with data can be tedious, and experts need to see the outcome of their efforts — whether it’s improving AI-driven risk assessments, optimising supply chain resilience, or enabling smarter decision-making. The key is to make data collaboration intuitive, purpose-driven, and directly tied to business outcomes, so experts remain engaged and motivated.
Intelligence: Making AI systems smarter
Once AI has access to high-quality data, the next challenge is ensuring it generates useful and accurate outputs. Domain expertise is needed to:
- Define clear AI objectives aligned with business priorities
- Ensure AI correctly interprets industry-specific data
- Continuously validate AI’s outputs and recommendations
Let’s look at some common AI approaches and see how they can benefit from an extra shot of domain knowledge.
Training predictive models from scratch
For structured problems like supply chain forecasting, predictive models such as classification and regression can help anticipate delays and suggest optimisations. However, to make sure these models are aligned with business goals, data scientists and knowledge engineers need to work together. For example, an AI model might try to minimise shipment delays at all costs, but a supply chain expert knows that fast-tracking every shipment through air freight is financially unsustainable. They can formulate additional constraints on the model, making it prioritise critical shipments while balancing cost, risk, and lead times.
✅ Implementation tip: Define clear objectives and constraints with domain experts before training AI models, ensuring alignment with real business priorities.
For a detailed overview of predictive AI techniques, please refer to Chapter 4 of my book The Art of AI Product Management.
Navigating the LLM triad
While predictive models trained from scratch can excel at very specific tasks, they are also rigid and will “refuse” to perform any other task. GenAI models are more open-minded and can be used for highly diverse requests. For example, an LLM-based conversational widget in an SCO system can allow users to interact with real-time insights using natural language. Instead of sifting through inflexible dashboards, users can ask, “Which suppliers are at risk of delays?” or “What alternative routes are available?” The AI pulls from historical data, live logistics feeds, and external risk factors to provide actionable answers, suggest mitigations, and even automate workflows like rerouting shipments.
But how can you ensure that a huge, out-of-the-box model like ChatGPT or Llama understands the nuances of your domain? Let’s walk through the LLM triad — a progression of techniques to incorporate domain knowledge into your LLM system.
As you progress from left to right, you can ingrain more domain knowledge into the LLM — however, each stage also adds new technical challenges (if you are interested in a systematic deep-dive into the LLM triad, please check out chapters 5–8 of my book The Art of AI Product Management). Here, let’s focus on how domain experts can jump in at each of the stages:
- Prompting out-of-the-box LLMs might seem like a generic approach, but with the right intuition and skill, domain experts can fine-tune prompts to extract the extra bit of domain knowledge out of the LLM. Personally, I think this is a big part of the fascination around prompting — it puts the most powerful AI models directly into the hands of domain experts without any technical expertise. Some key prompting techniques include:
- Few-shot prompting: Incorporate examples to guide the model’s responses. Instead of just asking “What are alternative shipping routes?”, a well-crafted prompt includes sample scenarios, such as “Example of past scenario: A previous delay at the Port of Shenzhen was mitigated by rerouting through Ho Chi Minh City, reducing transit time by 3 days.”
- Chain-of-thought prompting: Encourage step-by-step reasoning for complex logistics queries. Instead of “Why is my shipment delayed?”, a structured prompt might be “Analyse historical delivery data, weather reports, and customs processing times to determine why shipment #12345 is delayed.”
- Providing further background information: Attach external documents to improve domain-specific responses. For example, prompts could reference real-time port congestion reports, supplier contracts, or risk assessments to generate data-backed recommendations. Most LLM interfaces already allow you to conveniently attach additional files to your prompt.
2. RAG (Retrieval-Augmented Generation): While prompting helps guide AI, it still relies on pre-trained knowledge, which may be outdated or incomplete. RAG allows AI to retrieve real-time, company-specific data, ensuring that its responses are grounded in current logistics reports, supplier performance records, and risk assessments. For example, instead of generating generic supplier risk analyses, a RAG-powered AI system would pull real-time shipment data, supplier credit ratings, and port congestion reports before making recommendations. Domain experts can help select and structure these data sources and are also needed when it comes to testing and evaluating RAG systems.
✅ Implementation tip: Work with domain experts to curate and structure knowledge sources — ensuring AI retrieves and applies only the most relevant and high-quality business information.
3. Fine-tuning: While prompting and RAG inject domain knowledge on-the-fly, they do not inherently embed supply domain-specific workflows, terminology, or decision logic into your LLM. Fine-tuning adapts the LLM to think like a logistics expert. Domain experts can guide this process by creating high-quality training data, ensuring AI learns from real supplier assessments, risk evaluations, and procurement decisions. They can refine industry terminology to prevent misinterpretations (e.g., AI distinguishing between “buffer stock” and “safety stock”). They also align AI’s reasoning with business logic, ensuring it considers cost, risk, and compliance — not just efficiency. Finally, they evaluate fine-tuned models, testing AI against real-world decisions to catch biases or blind spots.
✅ Implementation tip: In LLM fine-tuning, data is the crucial success factor. Quality goes over quantity, and fine-tuning on a small, high-quality dataset can give you excellent results. Thus, give your experts enough time to figure out the right structure and content of the fine-tuning data and plan for plenty of end-to-end iterations of your fine-tuning process.
Encoding expert knowledge with neuro-symbolic AI
Every machine learning algorithm gets it wrong from time to time. To mitigate errors, it helps to set the “hard facts” of your domain in stone, making your AI system more reliable and controllable. This combination of machine learning and deterministic rules is called neuro-symbolic AI.
For example, an explicit knowledge graph can encode supplier relationships, regulatory constraints, transportation networks, and risk dependencies in a structured, interconnected format.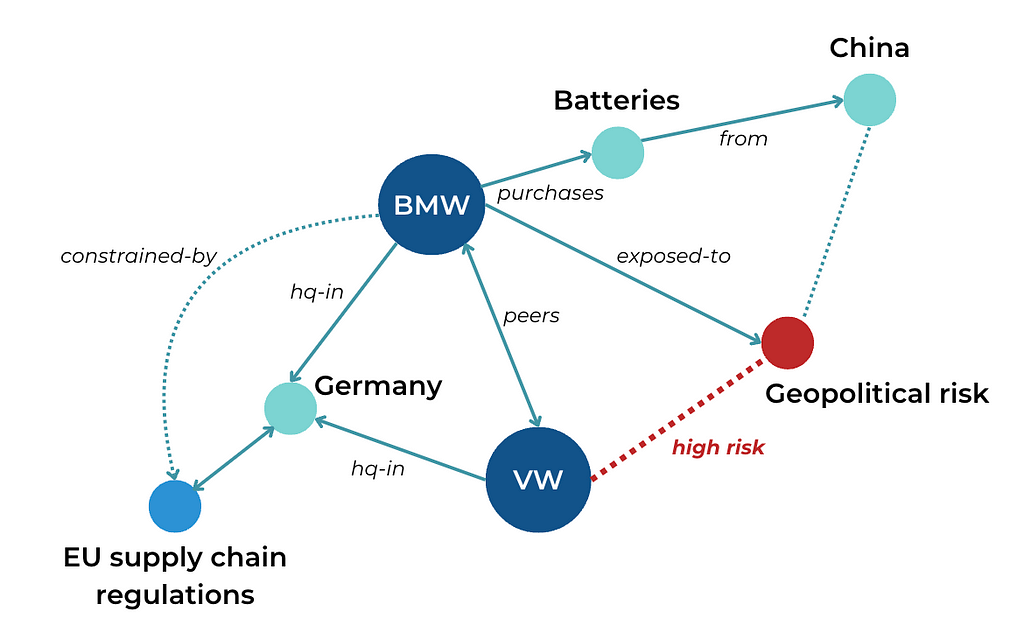
Instead of relying purely on statistical correlations, an AI system enriched with knowledge graphs can:
- Validate predictions against domain-specific rules (e.g., ensuring that AI-generated supplier recommendations comply with regulatory requirements).
- Infer missing information (e.g., if a supplier has no historical delays but shares dependencies with high-risk suppliers, AI can assess its potential risk).
- Improve explainability by allowing AI decisions to be traced back to logical, rule-based reasoning rather than black-box statistical outputs.
How can you decide which knowledge should be encoded with rules (symbolic AI), and which should be learned dynamically from the data (neural AI)? Domain experts can help youpick those bits of knowledge where hard-coding makes the most sense:
- Knowledge that is relatively stable over time
- Knowledge that is hard to infer from the data, for example because it is not well-represented
- Knowledge that is critical for high-impact decisions in your domain, so you can’t afford to get it wrong
In most cases, this knowledge will be stored in separate components of your AI system, like decision trees, knowledge graphs, and ontologies. There are also some methods to integrate it directly into LLMs and other statistical models, such as Lamini’s memory fine-tuning.
Compound AI and workflow engineering
Generating insights and turning them into actions is a multi-step process. Experts can help you model workflows and decision-making pipelines, ensuring that the process followed by your AI system aligns with their tasks. For example, the following pipeline shows how the AI components we considered so far can be combined into a workflow for the mitigation of shipment risks: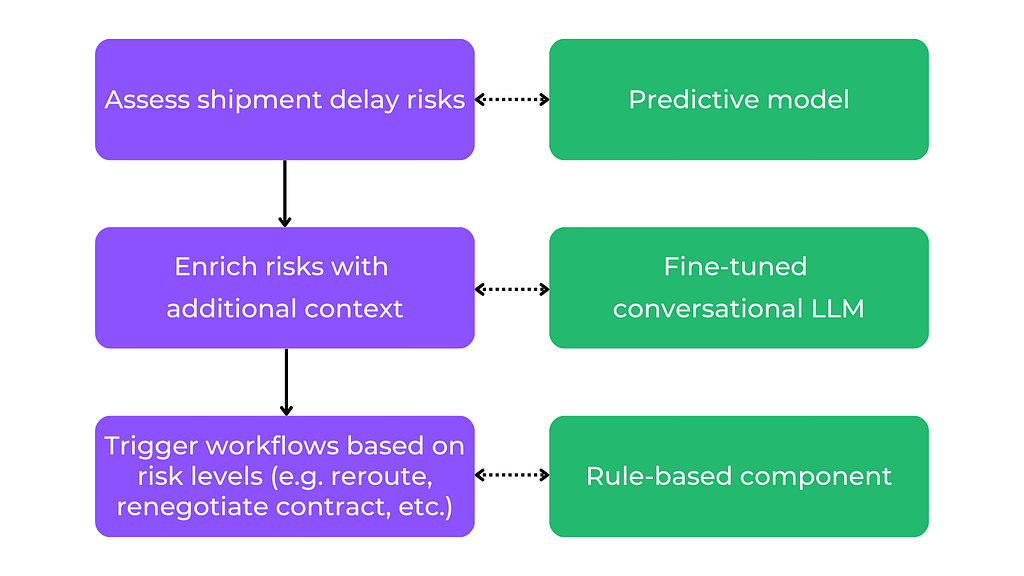
Experts are also needed to calibrate the “labor distribution” between humans in AI. For example, when modelling decision logic, they can set thresholds for automation, deciding when AI can trigger workflows versus when human approval is needed.
✅ Implementation tip: Involve your domain experts in mapping your processes to AI models and assets, identifying gaps vs. steps that can already be automated.
Designing ergonomic user experiences
Especially in B2B environments, where workers are deeply embedded in their daily workflows, the user experience must be seamlessly integrated with existing processes and task structures to ensure efficiency and adoption. For example, an AI-powered supply chain tool must align with how logistics professionals think, work, and make decisions. In the development phase, domain experts are the closest “peers” to your real users, and picking their brains is one of the fastest ways to bridge the gap between AI capabilities and real-world usability.
✅ Implementation tip: Involve domain experts early in UX design to ensure AI interfaces are intuitive, relevant, and tailored to real decision-making workflows.
Ensuring transparency and trust in AI decisions
AI thinks differently from humans, which makes us humans skeptical. Often, that’s a good thing since it helps us stay alert to potential mistakes. But distrust is also one of the biggest barriers to AI adoption. When users don’t understand why a system makes a particular recommendation, they are less likely to work with it. Domain experts can define how AI should explain itself — ensuring users have visibility into confidence scores, decision logic, and key influencing factors.
For example, if an SCO system recommends rerouting a shipment, it would be irresponsible on the part of a logistics planner to just accept it. She needs to see the “why” behind the recommendation — is it due to supplier risk, port congestion, or fuel cost spikes? The UX should show a breakdown of the decision, backed by additional information like historical data, risk factors, and a cost-benefit analysis.
⚠️ Mitigate overreliance on AI: Excessive dependence of your users on AI can introduce bias, errors, and unforeseen failures. Experts should find ways to calibrate AI-driven insights vs. human expertise, ethical oversight, and strategic safeguards to ensure resilience, adaptability, and trust in decision-making.
✅ Implementation tip: Work with domain experts to define key explainability features — such as confidence scores, data sources, and impact summaries — so users can quickly assess AI-driven recommendations.
Simplifying AI interactions without losing depth
AI tools should make complex decisions easier, not harder. If users need deep technical knowledge to extract insights from AI, the system has failed from a UX perspective. Domain experts can help strike a balance between simplicity and depth, ensuring the interface provides actionable, context-aware recommendations while allowing deeper analysis when needed.
For instance, instead of forcing users to manually sift through data tables, AI could provide pre-configured reports based on common logistics challenges. However, expert users should also have on-demand access to raw data and advanced settings when necessary. The key is to design AI interactions that are efficient for everyday use but flexible for deep analysis when required.
✅ Implementation tip: Use domain expert feedback to define default views, priority alerts, and user-configurable settings, ensuring AI interfaces provide both efficiency for routine tasks and depth for deeper research and strategic decisions.
Continuous UX testing and iteration with experts
AI UX isn’t a one-and-done process — it needs to evolve with real-world user feedback. Domain experts play a key role in UX testing, refinement, and iteration, ensuring that AI-driven workflows stay aligned with business needs and user expectations.
For example, your initial interface may surface too many low-priority alerts, leading to alert fatigue where users start ignoring AI recommendations. Supply chain experts can identify which alerts are most valuable, allowing UX designers to prioritize high-impact insights while reducing noise.
✅ Implementation tip: Conduct think-aloud sessions and have domain experts verbalize their thought process when interacting with your AI interface. This helps AI teams uncover hidden assumptions and refine AI based on how experts actually think and make decisions.
Conclusion
Vertical AI systems must integrate domain knowledge at every stage, and experts should become key stakeholders in your AI development:
- They refine data selection, annotation, and synthetic data.
- They guide AI learning through prompting, RAG, and fine-tuning.
- They support the design of seamless user experiences that integrate with daily workflows in a transparent and trustworthy way.
An AI system that “gets” the domain of your users will not only be useful and adopted in the short- and middle-term, but also contribute to the competitive advantage of your business.
Now that you have learned a bunch of methods to incorporate domain-specific knowledge, you might be wondering how to approach this in your organizational context. Stay tuned for my next article, where we will consider the practical challenges and strategies for implementing an expertise-driven AI strategy!
Note: Unless noted otherwise, all images are the author’s.
Injecting domain expertise into your AI system was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.









