










![From Gas Station to Google with Self-Taught Cloud Engineer Rishab Kumar [Podcast #158]](https://cdn.hashnode.com/res/hashnode/image/upload/v1738339892695/6b303b0a-c99c-4074-b4bd-104f98252c0c.png?#)























































The SCORES Framework: A Data Scientist’s Guide to Winning Target Variables
The missing manual for defining target variables that matter — bridge the gap between business goals and impactful ML modelsPhoto by Jeffrey F Lin on UnsplashPerfect accuracy on the wrong target variable is like acing the wrong exam- technically impressive, but missing the point entirely.Target variables or dependent variables are critical for the success of your machine learning model.When starting to work on a new model, most data scientists dive straight into model development, spending weeks engineering features, fine-tuning algorithms and optimizing hyper-parameters. Yet their models often struggle to get adoption and deliver business value.The result? Frustration, wasted time, and multiple rounds of rework.The root cause typically traces back to improperly defined target variables.The Hidden Complexity of Target VariablesData science literature typically focuses on model architecture while overlooking a crucial question:WHAT should the model predict?Discussions on supervised learning implicitly assume that the prediction objective is defined and that ground truth is readily available. Real-world business problems rarely come with clearly defined prediction objectives, creating several challenges such as :Misalignment between business goals and model predictionsPoor model performance requiring multiple iterations and increased development timeTheoretically accurate model results that do not pass the “sniff” testDifficulty influencing stakeholder adoptionThese challenges call for a systematic approach — one that bridges the gap between business goals and model performance. Enter the SCORES framework.Introducing the SCORES FrameworkThe SCORES framework is a systematic approach to defining and validating target variables for machine learning classification problems. It guides data scientists through six critical steps that ensure your target variable aligns with business objectives while maintaining model performance.S — Specify business goalsC — Choose the right metricO — Outline the measurement type,R — Restrict the event window,E — Evaluate metric thresholdsS — Simulate business impactImage generated by authorConsider FinTech First, a digital lending startup that offers credit cards to consumers and small business customers. As the startup evolved from its nascent stages and application volumes tripled, they turned to their data science team to automate the approvals process.The mission: build a machine learning model to identify risky applicants and approve only the creditworthy customers.The team’s first challenge? Define what makes a ‘risky’ customer.Let’s explore how each component of SCORES transforms ambiguous business problems into precise prediction targets, starting with the foundation: business alignment.S: Specify Business GoalsBefore diving into the model development process, every data scientist needs to connect with the product/business stakeholders and align on the business goals and expectations.Skipping this step can create a disconnect between the model’s capabilities and business needs.To ensure alignment,Ask about growth vs risk tolerance trade-offsDocument specific goals/success metrics served with the modelGather information about existing manual processesIn the case of FinTech First, their science team needed to know:What are the business goals? Do we want to target rapid expansion or enforce a tight control on losses (automation with minimal risk)?What processes exist for handling existing defaults?How do we define a bad customer?Do we have a target number of approvals or customer acquisitions from which we are working backwards?Investing the time to ask such questions at the beginning is critical for ensuring model adoption and can go a long way toward reducing churn.Image generated by Author using Claude AIWith clear business objectives in hand, the next challenge is translating them into measurable metrics that your model can actually predict.C: Choose Metric for Classification LabelTarget metrics typically fall into one of three categories:Direct metrics that provide clear measurements : Total Past-due Amount ($), Total order amount of food ordered through the app ($), Total amount of orders on the e-commerce website ($)Time-based metrics that capture patterns : # late payments, # months with at least one order, # months with an active subscription, # orders/monthComposite metrics that balance multiple factors: Total Credit Loss (after recovery efforts), Annual profitability per customer (after costs), Number of site visits (with or without purchases),When evaluating trade-offs associated with different metrics, consider :Data Imbalance: Does the chosen metric create a significant class imbalance in the training data? How can this imbalance be addressed (e.g., sampling techniques, cost-sensitive learning)?Predictive Power: How well can the chosen metric help differentiate between the target classes?Business Implications: What are the potential consequences of false positives

The missing manual for defining target variables that matter — bridge the gap between business goals and impactful ML models
Perfect accuracy on the wrong target variable is like acing the wrong exam
- technically impressive, but missing the point entirely.
Target variables or dependent variables are critical for the success of your machine learning model.
When starting to work on a new model, most data scientists dive straight into model development, spending weeks engineering features, fine-tuning algorithms and optimizing hyper-parameters. Yet their models often struggle to get adoption and deliver business value.
The result? Frustration, wasted time, and multiple rounds of rework.
The root cause typically traces back to improperly defined target variables.
The Hidden Complexity of Target Variables
Data science literature typically focuses on model architecture while overlooking a crucial question:
WHAT should the model predict?
Discussions on supervised learning implicitly assume that the prediction objective is defined and that ground truth is readily available. Real-world business problems rarely come with clearly defined prediction objectives, creating several challenges such as :
- Misalignment between business goals and model predictions
- Poor model performance requiring multiple iterations and increased development time
- Theoretically accurate model results that do not pass the “sniff” test
- Difficulty influencing stakeholder adoption
These challenges call for a systematic approach — one that bridges the gap between business goals and model performance. Enter the SCORES framework.
Introducing the SCORES Framework
The SCORES framework is a systematic approach to defining and validating target variables for machine learning classification problems. It guides data scientists through six critical steps that ensure your target variable aligns with business objectives while maintaining model performance.
S — Specify business goals
C — Choose the right metric
O — Outline the measurement type,
R — Restrict the event window,
E — Evaluate metric thresholds
S — Simulate business impact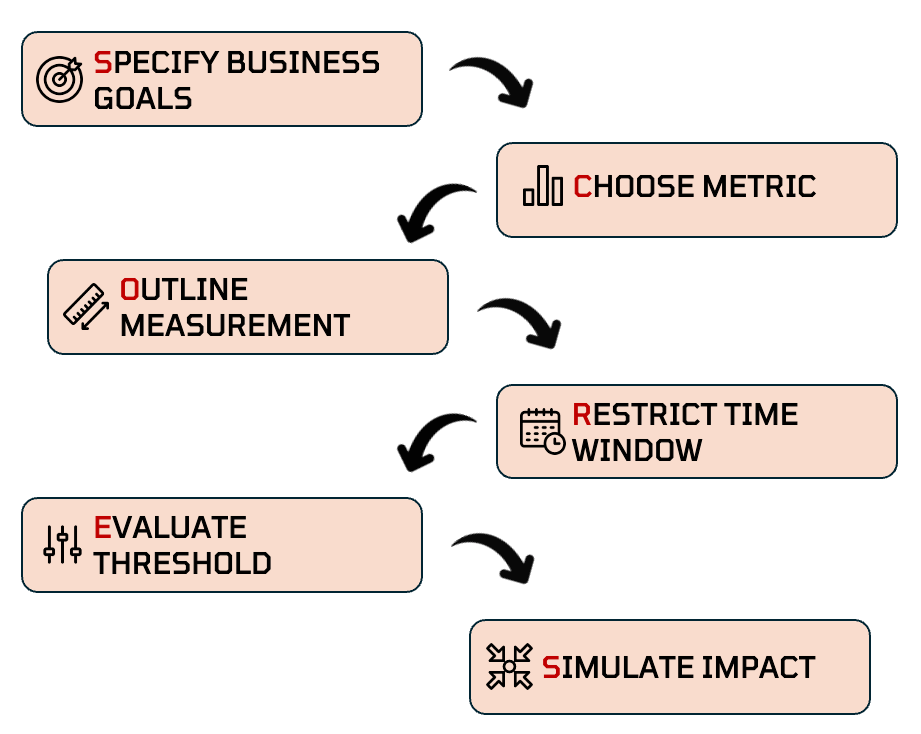
Consider FinTech First, a digital lending startup that offers credit cards to consumers and small business customers. As the startup evolved from its nascent stages and application volumes tripled, they turned to their data science team to automate the approvals process.
The mission: build a machine learning model to identify risky applicants and approve only the creditworthy customers.
The team’s first challenge? Define what makes a ‘risky’ customer.
Let’s explore how each component of SCORES transforms ambiguous business problems into precise prediction targets, starting with the foundation: business alignment.
S: Specify Business Goals
Before diving into the model development process, every data scientist needs to connect with the product/business stakeholders and align on the business goals and expectations.
Skipping this step can create a disconnect between the model’s capabilities and business needs.
To ensure alignment,
- Ask about growth vs risk tolerance trade-offs
- Document specific goals/success metrics served with the model
- Gather information about existing manual processes
In the case of FinTech First, their science team needed to know:
- What are the business goals? Do we want to target rapid expansion or enforce a tight control on losses (automation with minimal risk)?
- What processes exist for handling existing defaults?
- How do we define a bad customer?
- Do we have a target number of approvals or customer acquisitions from which we are working backwards?
Investing the time to ask such questions at the beginning is critical for ensuring model adoption and can go a long way toward reducing churn.
With clear business objectives in hand, the next challenge is translating them into measurable metrics that your model can actually predict.
C: Choose Metric for Classification Label
Target metrics typically fall into one of three categories:
- Direct metrics that provide clear measurements : Total Past-due Amount ($), Total order amount of food ordered through the app ($), Total amount of orders on the e-commerce website ($)
- Time-based metrics that capture patterns : # late payments, # months with at least one order, # months with an active subscription, # orders/month
- Composite metrics that balance multiple factors: Total Credit Loss (after recovery efforts), Annual profitability per customer (after costs), Number of site visits (with or without purchases),
When evaluating trade-offs associated with different metrics, consider :
- Data Imbalance: Does the chosen metric create a significant class imbalance in the training data? How can this imbalance be addressed (e.g., sampling techniques, cost-sensitive learning)?
- Predictive Power: How well can the chosen metric help differentiate between the target classes?
- Business Implications: What are the potential consequences of false positives (e.g., customer dissatisfaction, lost revenue, increased operational costs) vs false negatives (e.g., increased risk of losses, missed opportunities for intervention)? Is one inaccuracy more expensive to the business than the other?
- Alignment with Business Objectives/Processes: How well does the chosen metric align with key business objectives (e.g., revenue growth, customer retention, risk mitigation) and processes (e.g. suspension, write-off, activation, marketing policies)?
- Data Availability and Quality: Is data for the chosen metric readily available and of sufficient quality? Could the metric be biased towards one segment of the customer base than the other?









