










![From Gas Station to Google with Self-Taught Cloud Engineer Rishab Kumar [Podcast #158]](https://cdn.hashnode.com/res/hashnode/image/upload/v1738339892695/6b303b0a-c99c-4074-b4bd-104f98252c0c.png?#)























































Pirate Libraries Are Forbidden Fruit for AI Companies. But at What Cost?
The future of AI innovation may hinge on the outcome of a global copyright debate. In the U.S., rightsholders are taking a hard line, pursuing legal action against AI companies that utilize copyrighted works without permission. However, other countries are adopting more lenient approaches, allowing AI models to learn from the vast troves of data found in 'pirate' libraries. This 'copyright schism' could have far-reaching consequences. From: TF, for the latest news on copyright battles, piracy and more.

 Earlier this week, various rightsholder groups submitted their recommendations for the 2025 Special 301 Report.
Earlier this week, various rightsholder groups submitted their recommendations for the 2025 Special 301 Report.
This annual overview, compiled by the U.S. Trade Representative, highlights countries that fail to live up to U.S. copyright protection standards.
Various groups stressed the importance of copyright protection when it comes to new AI technologies. They argued that foreign governments should be mindful of potential copyright infringements.
The Chinese government is called out, for example, for considering the introduction of a text and data mining (TDM) exception for AI. Other countries, including Japan, have already written AI exceptions into law. This raises concerns. Not just for copyright holders, but also for American tech giants.
Tech Companies & Pirate Libraries
In the United States, explicit copyright exceptions for AI learning are non-existent. On the contrary, there are several high-profile lawsuits in the U.S. where tech companies including Meta, OpenAI, and Google are accused of copyright infringement.
Rightsholders accuse these companies of training their LLMs (large language models) on content obtained from unauthorized sources, including pirate libraries. These repositories turned out to be a goldmine, as they contained a vast amount of text, free for the taking. The problem, however, is that copyright holders never gave permission to use it.
The lawsuits will ultimately determine whether the tech companies are liable for copyright infringement, linked to this and other unauthorized use, or whether ‘fair use’ is a valid defense.
It will take years before those cases are decided and, meanwhile, pirate libraries such as Z-Library, LibGen, and Anna’s Archive are off limits. In countries where the law is more lenient or opaque, this might be an entirely different story. That could create a copyright schism with potentially far-reaching consequences.
DeepSeek ♡ Anna’s Archive
This week, hundreds of new articles were published on the latest AI model released by the Chinese company DeepSeek. This model isn’t just accurate, it’s also much cheaper to run, while significantly decreasing AI development costs.
According to pundits, Deepseek poses a threat to American AI dominance and leadership. While early responses are often overblown, it shows that AI development is a serious, high stakes business.
While DeepSeek’s innovation doesn’t stem from shadow libraries, the company did use them as key input. Recent publications have been less transparent about their data sources, but an earlier paper clearly mentions a reliance on Anna’s Archive.
“We cleaned 860K English and 180K Chinese e-books from Anna’s Archive,” a DeepSeek VL paper, published last March, states.
AI Teams Work with Anna’s Archive
DeepSeek isn’t alone in this. According to Anna’s Archive, many AI teams, including those connected to large U.S. and Chinese companies, have reached out to the site, looking for fast access to data.
Anna’s Archive offers to work with AI companies in return for a generous donation or a data trade. While U.S. companies typically back off due to copyright concerns, other teams gladly work with the shadow library.
“We’ve provided about 20-30 companies/teams with our entire dataset. It’s the same data as on our torrents page, but they get access to high-speed SFTP servers.”
“Usually, this is in exchange for a large monetary donation or, on occasion, in exchange for good datasets they acquired,” ‘Anna’s Archivist’ adds, noting that all data they obtain is shared publicly.
The shadow library provided copies of several redacted emails where companies requested access. We couldn’t independently verify their authenticity, but they are worth sharing nonetheless. ‘
“We are a research group from REDACTED, currently focusing on large language models (LLM) and in the process of data investigation. We are very interested in the high-quality resources you offer and would like to know more about the specifics.” – Chinese company
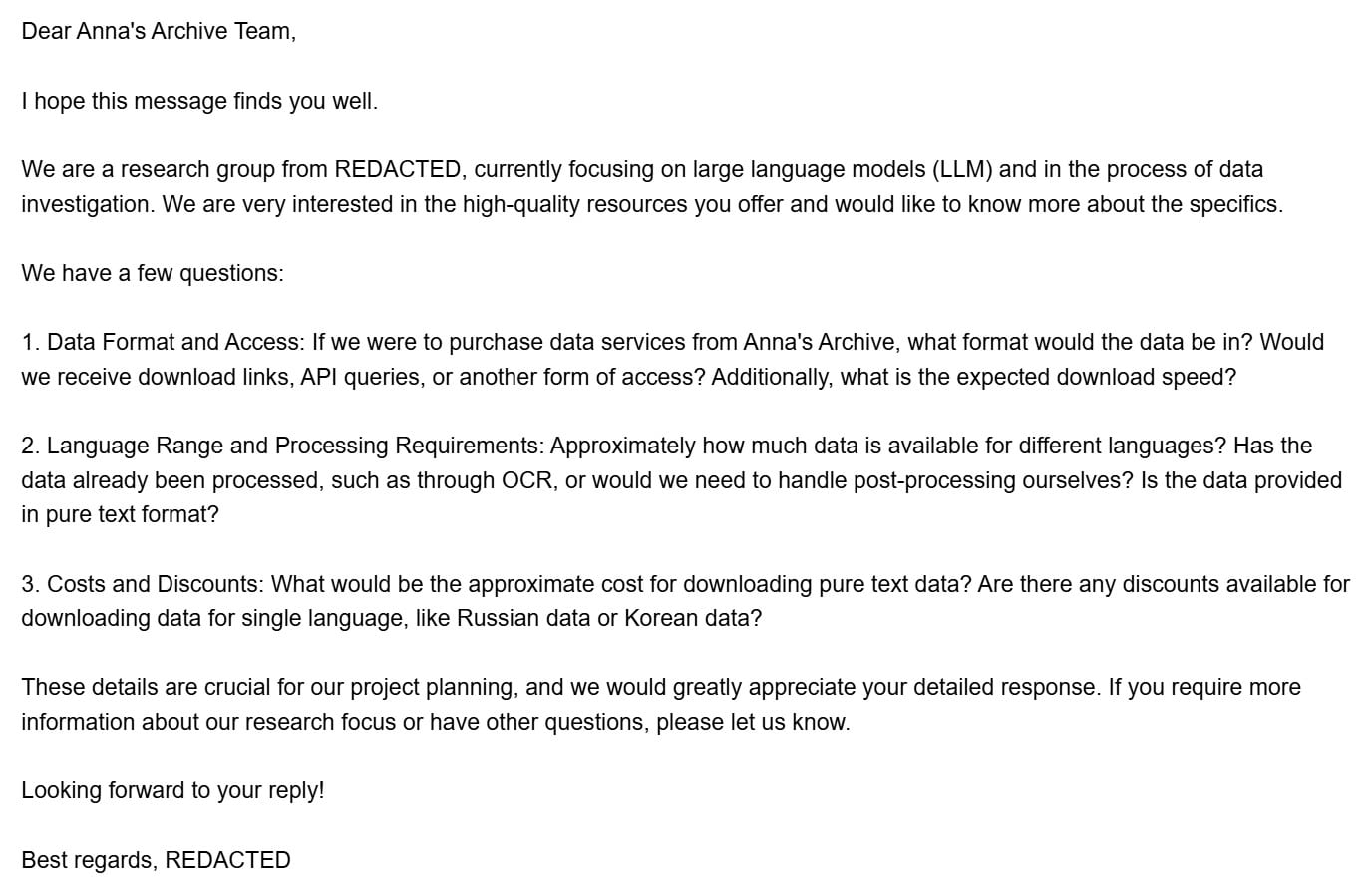
“We saw your Twitter post about the 7.5M scanned Chinese academic non-fiction book collection you are offering for LLM training if that company contributes to digitizing them via OCR. We at REDACTED have state of the art OCR technology we can leverage and would like to discuss this with you. We are happy to share sample results and open source all the results, but would likely ask to keep our code/pipeline proprietary.” – US company.
The “Forbidden Fruit”
Faced with multi-million dollar lawsuits, large U.S. companies are no longer eager to work with Anna’s Archive. However, AI teams in other countries are less reluctant, and that creates tension.
The allure of shadow libraries for AI development is akin to the biblical forbidden fruit. Just as Adam and Eve were tempted by the tree of knowledge, AI developers are drawn to the vast troves of ‘free’ data within these unauthorized collections.
Shadow libraries, filled with pirated works, offer the potential to train powerful AI models. However, like the original forbidden fruit, these shadow libraries come with a cost, at least for some.
In the U.S., copyright laws and pressure from copyright holders, make AI companies hesitant to bite into this fruit, fearing legal repercussions. Reluctance could therefore place American AI development at a “knowledge disadvantage”.
Innovation: The AI Copyright Conundrum
Meanwhile, in countries with more lenient copyright exceptions for AI training, companies are free to indulge. They can feast on the knowledge offered by shadow libraries, potentially accelerating their AI capabilities and gaining a competitive edge.
This has the potential to create a “copyright schism,” where AI development in some countries surges ahead, fueled by readily available data, while others are held back by legal constraints.
Without offering a value judgement, or engaging in too much hyperbole, this situation raises complex questions about the balance between protecting intellectual property and fostering innovation.
Is it fair for some countries to have a knowledge advantage due to differing copyright laws? Could this lead to a global AI divide, where certain nations dominate the field due to their access to “forbidden” data?
We don’t have the answers to any of these questions. As highlighted earlier, rightsholders believe that more strict AI regulation worldwide is the answer. If AI companies want access, they can negotiate deals and pay for it.
However, the shadow library understandably has a quite different take.
“This could be a geopolitical argument for the West relaxing copyright rules. If the West wants to stay ahead in AI, archiving and distributing books should be made fully legal,” ‘Anna’s Archivist’ informs us.
From: TF, for the latest news on copyright battles, piracy and more.









