




































































Designing, Building & Deploying an AI Chat App from Scratch (Part 2)
Cloud Deployment and ScalingPhoto by Alex wong on Unsplash1. IntroductionIn the previous post, we built an AI-powered chat application on our local computer using microservices. Our stack included FastAPI, Docker, Postgres, Nginx and llama.cpp. The goal of this post is to learn more about the fundamentals of cloud deployment and scaling by deploying our app to Azure, making it available to real users. We’ll use Azure because they offer a free education account, but the process is similar for other platforms like AWS and GCP.You can check a live demo of the app at chat.jorisbaan.nl. Now, obviously, this demo isn’t very large-scale, because the costs ramp up very quickly. With the tight scaling limits I configured I reckon it can handle about 10–40 concurrent users until I run out of Azure credits. However, I do hope it demonstrates the principles behind a scalable production system. We could easily configure it to scale to many more users with a higher budget.I give a complete breakdown of our infrastructure and the costs at the end. The codebase is at https://github.com/jsbaan/ai-app-from-scratch.A quick demo of the app at chat.jorisbaan.nl. We start a new chat, come back to that same chat, and start another chat.1.1. Recap: local applicationLet’s recap how we built our local app: A user can start or continue a chat with a language model by sending an HTTP request to http://localhost. An Nginx reverse proxy receives and forwards the request to a UI over a private Docker network. The UI stores a session cookie to identify the user, and sends requests to the backend: the language model API that generates text, and the database API that queries the database server.Local architecture of the app. See part 1 for more details. Made by author in draw.io.Table of contentsIntroduction1.1 Recap: local applicationCloud architecture2.1 Scaling2.2 Kubernetes Concepts2.3 Azure Container Apps2.4 Azure architecture: putting it all togetherDeployment3.1 Setting up3.2 PostgreSQL server deployment3.3 Azure Container App Environment deployment3.4 Azure Container Apps deployment3.5 Scaling our Container Apps3.6 Custom domain name & HTTPSResources & costs overviewRoadmapFinal thoughtsAcknowledgementsAI usage2. Cloud architectureConceptually, our cloud architecture will not be too different from our local application: a bunch of containers in a private network with a gateway to the outside world, our users.However, instead of running containers on our local computer with Docker Compose, we will deploy them to a computing environment that automatically scales across virtual or psychical machines to many concurrent users.2.1 ScalingScaling is a central concept in cloud architectures. It means being able to dynamically handle varying numbers of users (i.e., HTTP requests). Uvicorn, the web server running our UI and database API, can already handle about 40 concurrent requests. It’s even possible to use another web server called Gunicorn as a process manager that employs multiple Uvicorn workers in the same container, further increasing concurrency.Now, if we want to support even more concurrent request, we could give each container more resources, like CPUs or memory (vertical scaling). However, a more reliable approach is to dynamically create copies (replicas) of a container based on the number of incoming HTTP requests or memory/CPU usage, and distribute the incoming traffic across replicas (horizontal scaling). Each replica container will be assigned an IP address, so we also need to think about networking: how to centrally receive all requests and distribute them over the container replicas.This “prism” pattern is important: requests arrive centrally in some server (a load balancer) and fan out for parallel processing to multiple other servers (e.g., several identical UI containers).Photo of two prisms by Fernando @cferdophotography on Unsplash2.2 Kubernetes ConceptsKubernetes is the industry standard system for automating deployment, scaling and management of containerized applications. Its core concepts are crucial to understand modern cloud architectures, including ours, so let’s quickly review the basics.Node: A physical or virtual machine to run containerized app or manage the cluster.Cluster: A set of Nodes managed by Kubernetes.Pod: The smallest deployable unit in Kubernetes. Runs one main app container with optional secondary containers that share storage and networking.Deployment: An abstraction that manages the desired state of a set of Pod replicas by deploying, scaling and updating them.Service: An abstraction that manages a stable entrypoint (the service’s DNS name) to expose a set of Pods by distributing incoming traffic over the various dynamic Pod IP addresses. A Service has multiple types:- A ClusterIP Service exposes Pods within the Cluster- A LoadBalancer Service exposes Pods to outside the Cluster. It triggers the cloud provider to provision an external public IP and load balancer outside the cluster that can

Cloud Deployment and Scaling
1. Introduction
In the previous post, we built an AI-powered chat application on our local computer using microservices. Our stack included FastAPI, Docker, Postgres, Nginx and llama.cpp. The goal of this post is to learn more about the fundamentals of cloud deployment and scaling by deploying our app to Azure, making it available to real users. We’ll use Azure because they offer a free education account, but the process is similar for other platforms like AWS and GCP.
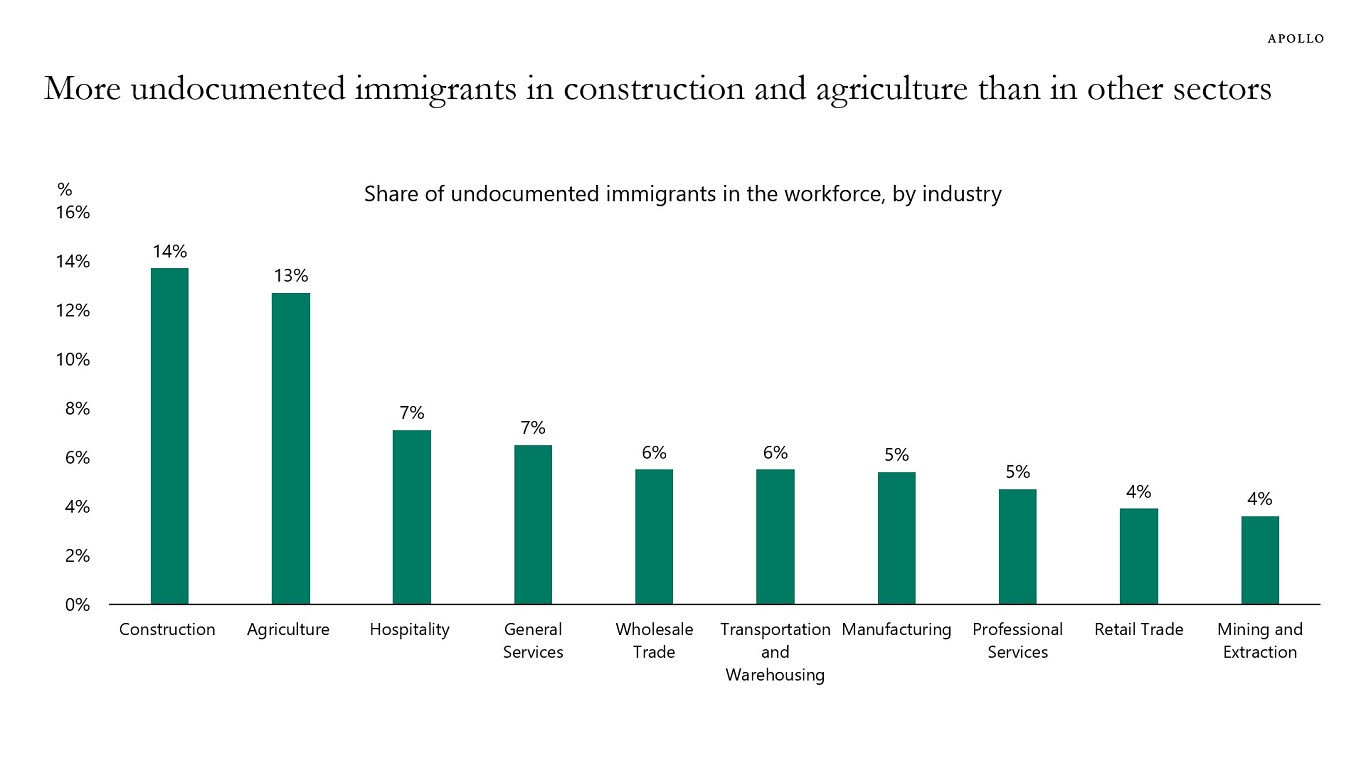
You can check a live demo of the app at chat.jorisbaan.nl. Now, obviously, this demo isn’t very large-scale, because the costs ramp up very quickly. With the tight scaling limits I configured I reckon it can handle about 10–40 concurrent users until I run out of Azure credits. However, I do hope it demonstrates the principles behind a scalable production system. We could easily configure it to scale to many more users with a higher budget.
I give a complete breakdown of our infrastructure and the costs at the end. The codebase is at https://github.com/jsbaan/ai-app-from-scratch.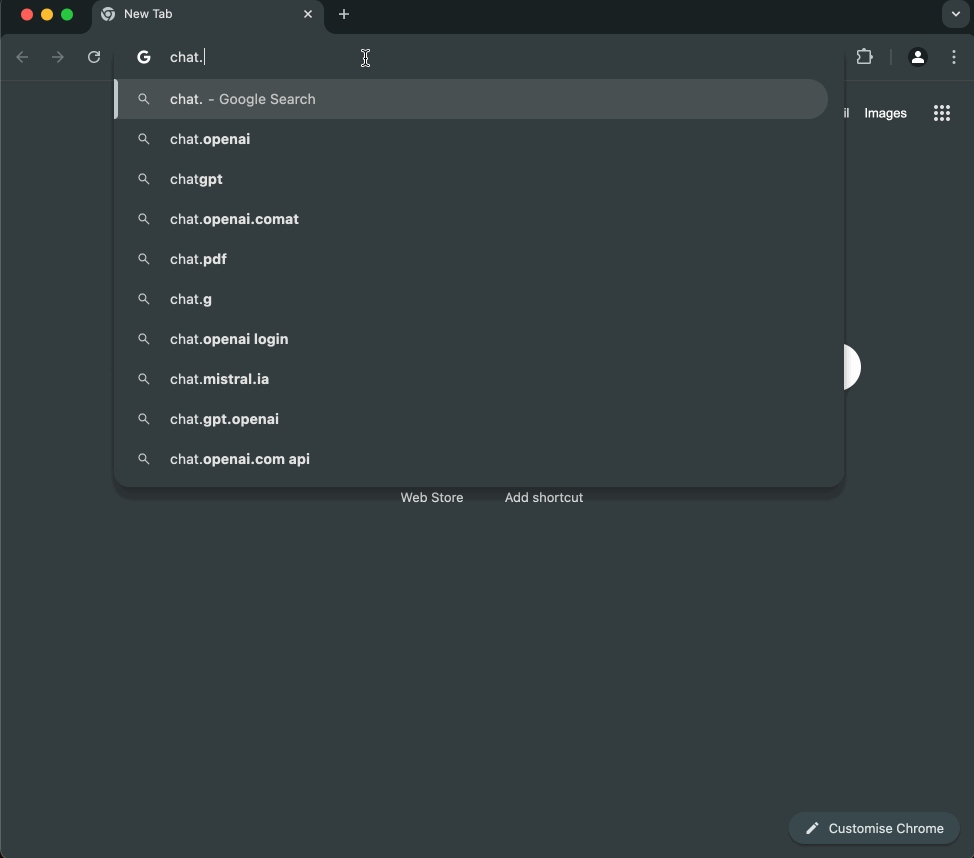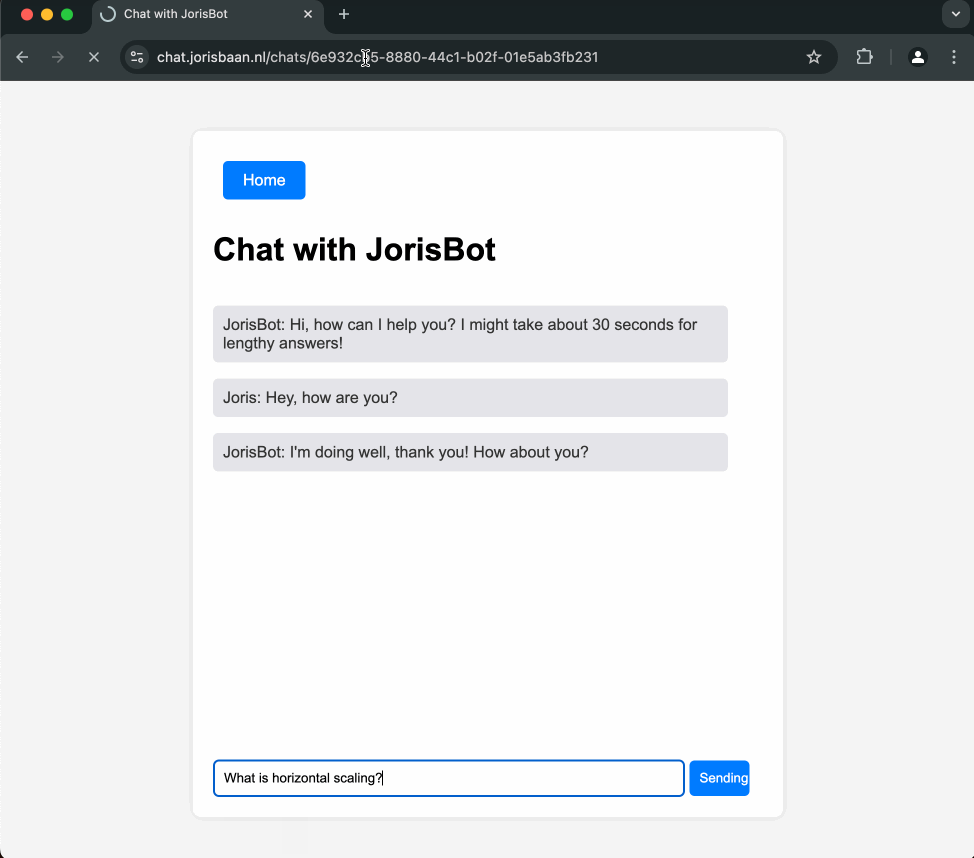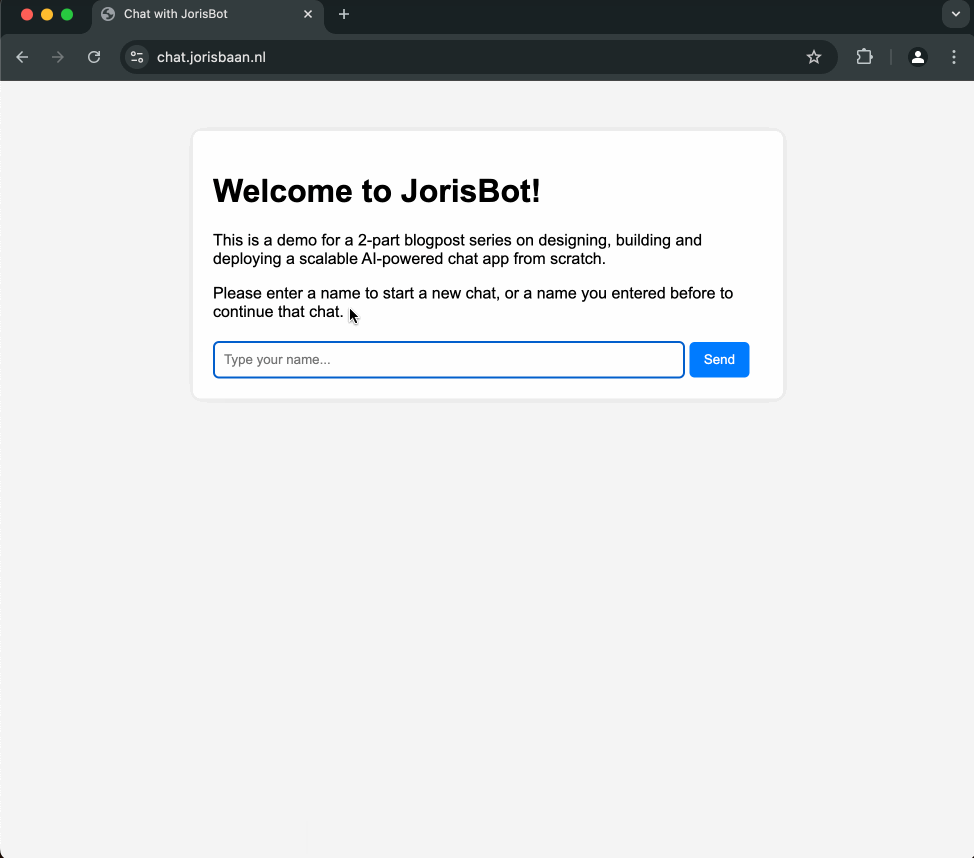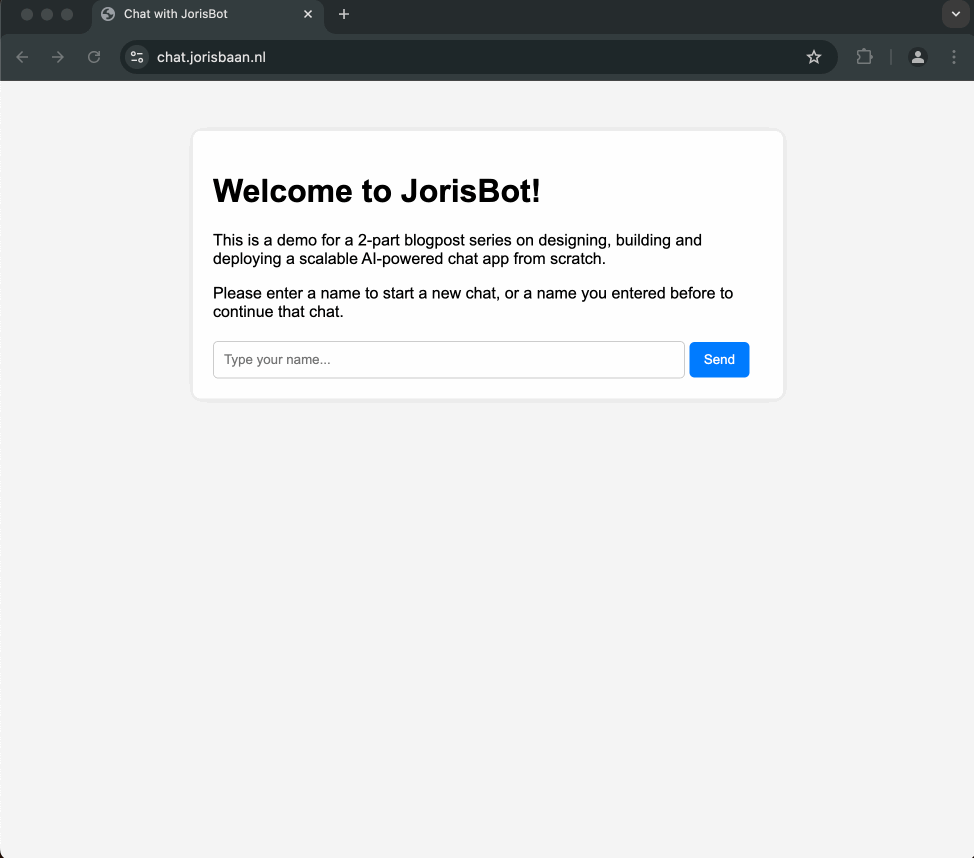
1.1. Recap: local application
Let’s recap how we built our local app: A user can start or continue a chat with a language model by sending an HTTP request to http://localhost. An Nginx reverse proxy receives and forwards the request to a UI over a private Docker network. The UI stores a session cookie to identify the user, and sends requests to the backend: the language model API that generates text, and the database API that queries the database server.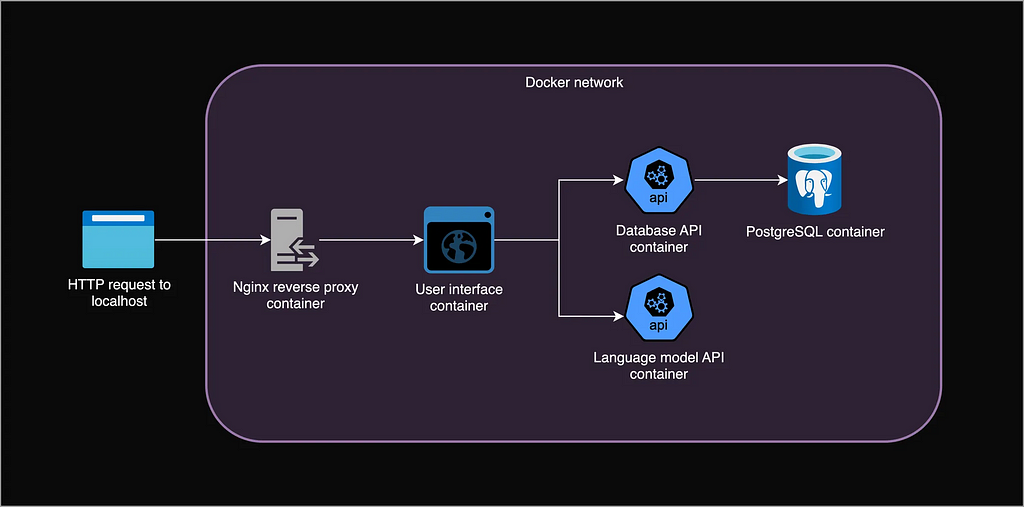
Table of contents
- Introduction
1.1 Recap: local application - Cloud architecture
2.1 Scaling
2.2 Kubernetes Concepts
2.3 Azure Container Apps
2.4 Azure architecture: putting it all together - Deployment
3.1 Setting up
3.2 PostgreSQL server deployment
3.3 Azure Container App Environment deployment
3.4 Azure Container Apps deployment
3.5 Scaling our Container Apps
3.6 Custom domain name & HTTPS - Resources & costs overview
- Roadmap
- Final thoughts
Acknowledgements
AI usage
2. Cloud architecture
Conceptually, our cloud architecture will not be too different from our local application: a bunch of containers in a private network with a gateway to the outside world, our users.
However, instead of running containers on our local computer with Docker Compose, we will deploy them to a computing environment that automatically scales across virtual or psychical machines to many concurrent users.
2.1 Scaling
Scaling is a central concept in cloud architectures. It means being able to dynamically handle varying numbers of users (i.e., HTTP requests). Uvicorn, the web server running our UI and database API, can already handle about 40 concurrent requests. It’s even possible to use another web server called Gunicorn as a process manager that employs multiple Uvicorn workers in the same container, further increasing concurrency.
Now, if we want to support even more concurrent request, we could give each container more resources, like CPUs or memory (vertical scaling). However, a more reliable approach is to dynamically create copies (replicas) of a container based on the number of incoming HTTP requests or memory/CPU usage, and distribute the incoming traffic across replicas (horizontal scaling). Each replica container will be assigned an IP address, so we also need to think about networking: how to centrally receive all requests and distribute them over the container replicas.
This “prism” pattern is important: requests arrive centrally in some server (a load balancer) and fan out for parallel processing to multiple other servers (e.g., several identical UI containers).

2.2 Kubernetes Concepts
Kubernetes is the industry standard system for automating deployment, scaling and management of containerized applications. Its core concepts are crucial to understand modern cloud architectures, including ours, so let’s quickly review the basics.
- Node: A physical or virtual machine to run containerized app or manage the cluster.
- Cluster: A set of Nodes managed by Kubernetes.
- Pod: The smallest deployable unit in Kubernetes. Runs one main app container with optional secondary containers that share storage and networking.
- Deployment: An abstraction that manages the desired state of a set of Pod replicas by deploying, scaling and updating them.
- Service: An abstraction that manages a stable entrypoint (the service’s DNS name) to expose a set of Pods by distributing incoming traffic over the various dynamic Pod IP addresses. A Service has multiple types:
- A ClusterIP Service exposes Pods within the Cluster
- A LoadBalancer Service exposes Pods to outside the Cluster. It triggers the cloud provider to provision an external public IP and load balancer outside the cluster that can be used to reach the cluster. These external requests are then routed via the Service to individual Pods. - Ingress: An abstraction that defines more complex rules for a cluster’s entrypoint. It can route traffic to multiple Services; give Services externally-reachable URLs; load balance traffic; and handle secure HTTPS.
- Ingress Controller: Implements the Ingress rules. For example, an Nginx-based controller runs an Nginx server (like in our local app) under the hood that is dynamically configured to route traffic according to Ingress rules. To expose the Ingress Controller itself to the outside world, you can use a LoadBalancer Service. This architecture is often used.
2.3 Azure Container Apps
Armed with these concepts, instead of deploying our app with Kubernetes directly, I wanted to experiment a little by using Azure Container Apps (ACA). This is a serverless platform built on top of Kubernetes that abstracts away some of its complexity.
With a single command, we can create a Container App Environment, which, under the hood, is an invisible Kubernetes Cluster managed by Azure. Within this Environment, we can run a container as a Container App that Azure internally manages as Kubernetes Deployments, Services, and Pods. See article 1 and article 2 for detailed comparisons.
A Container App Environment also auto-creates:
- An invisible Envoy Ingress Controller that routes requests to internal Apps and handles HTTPS and App auto-scaling based on request volume.
- An external Public IP address and Azure Load Balancer that routes external traffic to the Ingress Controller that in turn routes it to Apps (sounds similar to a Kubernetes LoadBalancer Service, eh?).
- An Azure-generated URL for each Container App that is publicly accessible over the internet or internal, based on its Ingress config.
This gives us everything we need to run our containers at scale. The only thing missing is a database. We will use an Azure-managed PostgreSQL server instead of deploying our own container, because it’s easier, more reliable and scalable. Our local Nginx reverse proxy container is also obsolete because ACA automatically deploys an Envoy Ingress Controller.
It’s interesting to note that we literally don’t have to change a single line of code in our local application, we can just treat it as a bunch of containers!
2.4 Azure architecture: putting it all together
Here is a diagram of the full cloud architecture for our chat application that contains all our Azure resources. Let’s take a high level look at how a user request flows through the system.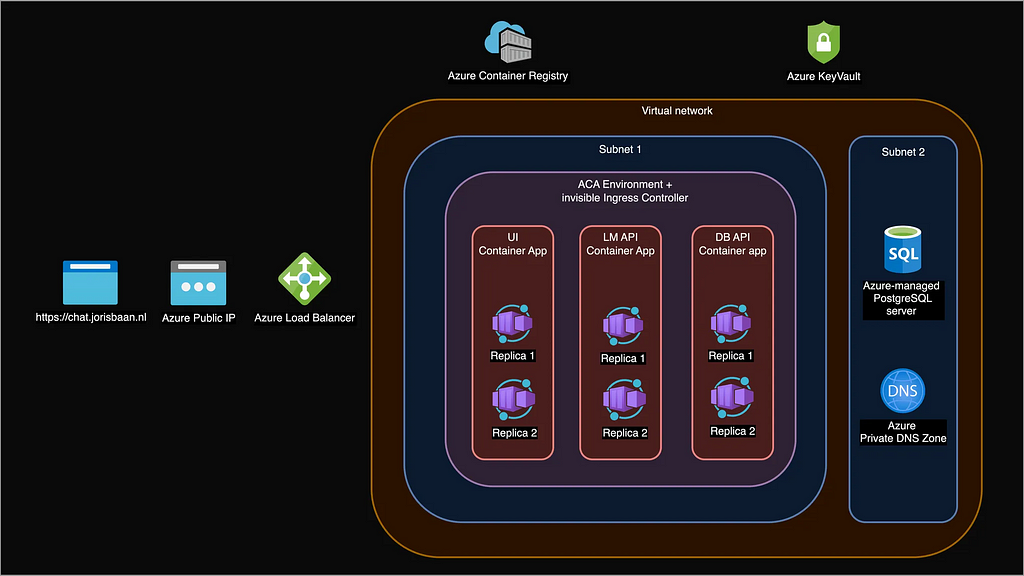
- User sends HTTPS request to chat.jorisbaan.nl.
- A Public DNS server like Google DNS resolves this domain name to an Azure Public IP address.
- The Azure Load Balancer on this IP address routes the request to the (for us invisible) Envoy Ingress Controller.
- The Ingress Controller routes the request to UI Container App, who routes it to one of its Replicas where a UI web server is running.
- The UI web server makes requests to the database API and language model API Apps, who both route it to one of their Replicas.
- A database API replica queries the PostgreSQL server hostname. The Azure Private DNS Zone resolves the hostname to the PostgreSQL server’s IP address.
3. Deployment
So, how do we actually create all this? Rather than clicking around in the Azure Portal, infrastructure-as-code tools like Terraform are best to create and manage cloud resources. However, for simplicity, I will instead use the Azure CLI to create a bash script that deploys our entire application step by step. You can find the full deployment script including environment variables here


![iPhone SE Stock Running Low as New Model Launch Nears [Gurman]](https://www.iclarified.com/images/news/96170/96170/96170-640.jpg)
