












































Data logs: The latest evolution in Meta’s access tools
We’re sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. Users have a variety [...] Read More... The post Data logs: The latest evolution in Meta’s access tools appeared first on Engineering at Meta.

- We’re sharing how Meta built support for data logs, which provide people with additional data about how they use our products.
- Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand.
Users have a variety of tools they can use to manage and access their information on Meta platforms. Meta is always looking for ways to enhance its access tools in line with technological advances, and in February 2024 we began including data logs in the Download Your Information (DYI) tool. Data logs include things such as information about content you’ve viewed on Facebook. Some of this data can be unique, but it can also include additional details about information that we already make available elsewhere, such as through a user’s profile, products like Access Your Information or Activity Log, or account downloads. This update is the result of significant investments over a number of years by a large cross-functional team at Meta, and consultations with experts on how to continue enhancing our access tools.
Data logs are just the most recent example of how Meta gives users the power to access their data on our platforms. We have a long history of giving users transparency and control over their data:
- 2010: Users can retrieve a copy of their information through DYI.
- 2011: Users can easily review actions taken on Facebook through Activity Log.
- 2014: Users have more transparency and control over ads they see with the “Why Am I Seeing This Ad?” feature on Facebook.
- 2018: Users have a curated experience to find information about them through Access Your Information. Users can retrieve a copy of their information on Instagram through Download Your Data and on WhatsApp through Request Account Information.
- 2019: Users can view their activity off Meta-technologies and clear their history. Meta joins the Data Transfer Project and has continuously led the development of shared technologies that enable users to port their data from one platform to another.
- 2020: Users continue to receive more information in DYI such as additional information about their interactions on Facebook and Instagram.
- 2021: Users can more easily navigate categories of information in Access Your Information
- 2023: Users can more easily use our tools as access features are consolidated within Accounts Center.
- 2024: Users can access data logs in Download Your Information.
What are data logs?
In contrast to our production systems, which can be queried billions of times per second thanks to techniques like caching, Meta’s data warehouse, powered by Hive, is designed to support low volumes of large queries for things like analytics and cannot scale to the query rates needed to power real-time data access.
We created data logs as a solution to provide users who want more granular information with access to data stored in Hive. In this context, an individual data log entry is a formatted version of a single row of data from Hive that has been processed to make the underlying data transparent and easy to understand.
Obtaining this data from Hive in a format that can be presented to users is not straightforward. Hive tables are partitioned, typically by date and time, so retrieving all the data for a specific user requires scanning through every row of every partition to check whether it corresponds to that user. Facebook has over 3 billion monthly active users, meaning that, assuming an even distribution of data, ~99.999999967% of the rows in a given Hive table might be processed for such a query even though they won’t be relevant.
Overcoming this fundamental limitation was challenging, and adapting our infrastructure to enable it has taken multiple years of concerted effort. Data warehouses are commonly used in a range of industry sectors, so we hope that this solution should be of interest to other companies seeking to provide access to the data in their data warehouses.
Initial designs
When we started designing a solution to make data logs available, we first considered whether it would be feasible to simply run queries for each individual as they requested their data, despite the fact that these queries would spend almost all of their time processing irrelevant data. Unfortunately, as we highlighted above, the distribution of data at Meta’s scale makes this approach infeasible and incredibly wasteful: It would require scanning entire tables once per DYI request, scaling linearly with the number of individual users that initiate DYI requests. These performance characteristics were infeasible to work around.
We also considered caching data logs in an online system capable of supporting a range of indexed per-user queries. This would make the per-user queries relatively efficient. However, copying and storing data from the warehouse in these other systems presented material computational and storage costs that were not offset by the overall effectiveness of the cache, making this infeasible as well.
Current design
Finally, we considered whether it would be possible to build a system that relies on amortizing the cost of expensive full table scans by batching individual users’ requests into a single scan. After significant engineering investigation and prototyping, we determined that this system provides sufficiently predictable performance characteristics to infrastructure teams to make this possible. Even with this batching over short periods of time, given the relatively small size of the batches of requests for this information compared to the overall user base, most of the rows considered in a given table are filtered and scoped out as they are not relevant to the users whose data has been requested. This is a necessary trade off to enable this information to be made accessible to our users.
In more detail, following a pre-defined schedule, a job is triggered using Meta’s internal task-scheduling service to organize the most recent requests, over a short time period, for users’ data logs into a single batch. This batch is submitted to a system built on top of Meta’s Core Workflow Service (CWS). CWS provides a useful set of guarantees that enable long-running tasks to be executed with predictable performance characteristics and reliability guarantees that are critical for complex multi-step workflows.
Once the batch has been queued for processing, we copy the list of user IDs who have made requests in that batch into a new Hive table. For each data logs table, we initiate a new worker task that fetches the relevant metadata describing how to correctly query the data. Once we know what to query for a specific table, we create a task for each partition that executes a job in Dataswarm (our data pipeline system). This job performs an INNER JOIN between the table containing requesters’ IDs and the column in each table that identifies the owner of the data in that row. As tables in Hive may leverage security mechanisms like access control lists (ACLs) and privacy protections built on top of Meta’s Privacy Aware Infrastructure, the jobs are configured with appropriate security and privacy policies that govern access to the data.
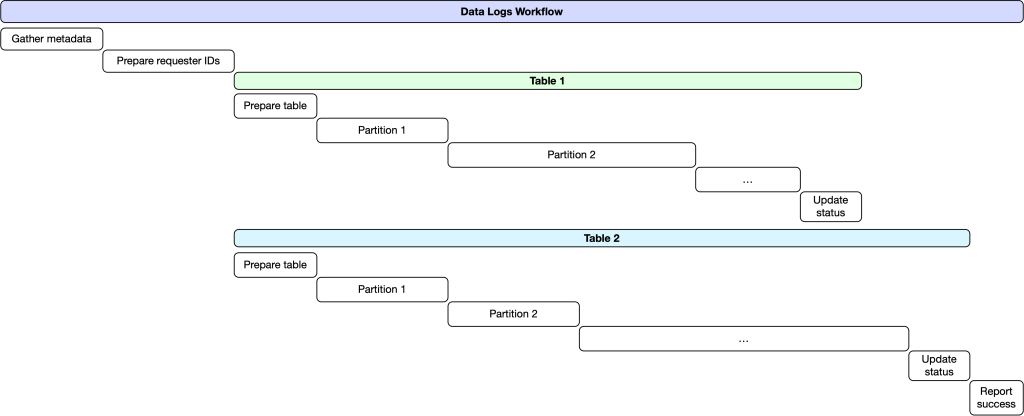
Once this job is completed, it outputs its results to an intermediate Hive table containing a combination of the data logs for all users in the current batch. This processing is expensive, as the INNER JOIN requires a full table scan across all relevant partitions of the Hive table, an operation which may consume significant computational resources. The output table is then processed using PySpark to identify the relevant data and split it into individual files for each user’s data in a given partition.
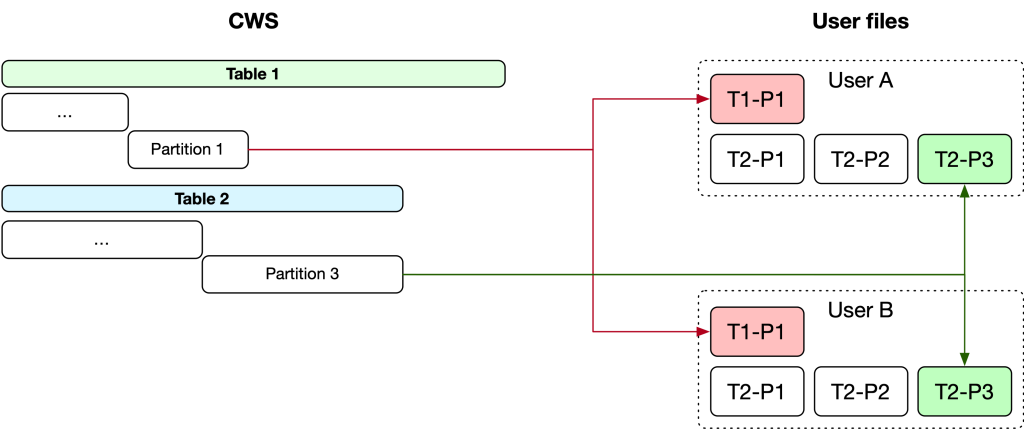
The result of these batch operations in the data warehouse is a set of comma delimited text files containing the unfiltered raw data logs for each user. This raw data is not yet explained or made intelligible to users, so we run a post-processing step in Meta’s Hack language to apply privacy rules and filters and render the raw data into meaningful, well-explained HTML files. We do this by passing the raw data through various renderers, discussed in more detail in the next section. Finally, once all of the processing is completed, the results are aggregated into a ZIP file and made available to the requestor through the DYI tool.
Lessons learned from building data logs
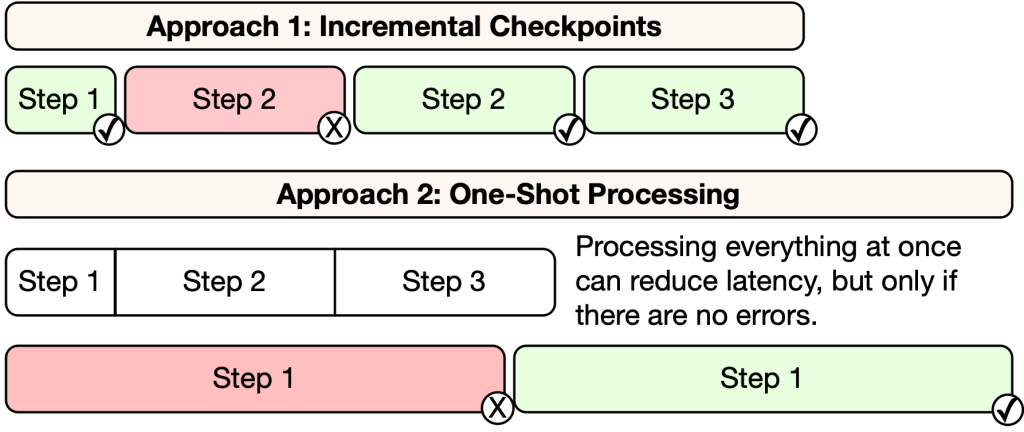
Throughout the development of this system we found it critical to develop robust checkpointing mechanisms that enable incremental progress and resilience in the face of errors and temporary failures. While processing everything in a single pass may reduce latency, the risk is that a single issue will cause all of the previous work to be wasted. For example, in addition to jobs timing out and failing to complete, we also experienced errors where full-table-scan queries would run out of memory and fail partway through processing. The capability to resume work piecemeal increases resiliency and optimizes the overall throughput of the system.
Ensuring data correctness is also very important. As we built the component that splits combined results into individual files for each user, we encountered an issue that affected this correctness guarantee and could have led to data being returned to the wrong user. The root cause of the issue was a Spark concurrency bug that partitioned data incorrectly across the parallel Spark workers. To prevent this issue, we built verification in the post-processing stage to ensure that the user ID column in the data matches the identifier for the user whose logs we are generating. This means that even if similar bugs were to occur in the core data processing infrastructure we would prevent any incorrect data from being shown to users.
Finally, we learned that complex data workflows require advanced tools and the capability to iterate on code changes quickly without re-processing everything. To this end, we built an experimentation platform that enables running modified versions of the workflows to quickly test changes, with the ability to independently execute phases of the process to expedite our work. For example, we found that innocent-looking changes such as altering which column is being fetched can lead to complex failures in the data fetching jobs. We now have the ability to run a test job under the new configuration when making a change to a table fetcher.
Making data consistently understandable and explainable
Meta cares about ensuring that the information we provide is meaningful to end-users. A key challenge in providing transparent access is presenting often highly technical information in a way that is approachable and easy to understand, even for those with little expertise in technology.
Providing people access to their data involves working across numerous products and surfaces that our users interact with every day. The way that information is stored on our back-end systems is not always directly intelligible to end-users, and it takes both understanding of the individual products and features as well as the needs of users to make it user-friendly. This is a large, collaborative undertaking, leveraging many forms of expertise. Our process entails working with product teams familiar with the data from their respective products, applying our historical expertise in access surfaces, using innovative tools we have developed, and consulting with experts.
In more detail, a cross-functional team of access experts works with specialist teams to review these tables, taking care to avoid exposing information that could adversely affect the rights and freedoms of other users. For example, if you block another user Facebook, this information would not be provided to the person that you have blocked. Similarly, when you view another user’s profile, this information will be available to you, but not the person whose profile you viewed. This is a key principle Meta upholds to respect the rights of everyone who engages with our platforms. It also means that we need a rigorous process to ensure that the data made available is never shared incorrectly. Many of the datasets that power a social network will reference more than one person, but that does not imply everyone referenced should always have equal access to that information.
Additionally, Meta must take care not to disclose information that may compromise our integrity or safety systems, or our intellectual property rights. For instance, Meta sends millions of NCMEC Cybertip reports per year to help protect children on our platforms. Disclosing this information, or the data signals used to detect apparent violations of laws protecting children, may undermine the sophisticated techniques we have developed to proactively seek out and report these types of content and interactions.
One particularly time consuming and challenging task is ensuring that Meta-internal text strings that describe our systems and products are translated into more easily human readable terms. For instance, a Hack enum could define a set of user interface element references. Exposing the jargon-heavy internal versions of these enums would definitely not be meaningful to an end-user — they may not be meaningful at first glance to other employees without sufficient context! In this case, user-friendly labels are created to replace these internal-facing strings. The resulting content is reviewed for explainability, simplicity, and consistency, with product experts also helping to verify that the final version is accurate.
This process makes information more useful by reducing duplicative information. When engineers build and iterate on a product for our platforms, they may log slightly different versions of the same information with the goal of better understanding how people use the product. For example, when users select an option from a list of actions, each part of the system may use slightly different values that represent the same underlying option, such as an option to move content to trash as part of Manage Activity. As a concrete example, we found this action stored with different values: In the first instance it was entered as MOVE_TO_TRASH, in the second as StoryTrashPostMenuItem, and in the third FBFeedMoveToTrashOption. These differences stemmed from the fact that the logging in question was coming from different parts of the system with different conventions. Through a series of cross-functional reviews with support from product experts, Meta determines an appropriate column header (e.g., “Which option you interacted with”), and the best label for the option (e.g., “Move to trash”).
Finally, once content has been reviewed, it can be implemented in code using the renderers we described above. These are responsible for reading the raw values and transforming them into user-friendly representations. This includes transforming raw integer values into meaningful references to entities and converting raw enum values into user-friendly representations. An ID like 1786022095521328 might become “John Doe”; enums with integer values 0, 1, 2, converted into text like “Disabled,” “Active,” or “Hidden;”and columns with string enums can remove jargon that is not understandable to end-users and de-duplicate (as in our “Move to trash” example above).
Together, these culminate in a much friendlier representation of the data that might look like this:

The post Data logs: The latest evolution in Meta’s access tools appeared first on Engineering at Meta.